Interpreting Deep Policies via Critical States
ABOUT THE PROJECT
At a glance
Teaching a robot or agent to perform difficult tasks often involves learning complex policies, that are essentially black boxes. This makes it difficult for humans, including robot designers, to interpret what high-level features these policies reason about and how they make decisions.
Making it easier to understand and interpret policies would enable researchers and end-users to better predict how the policy will generalize well to novel states, not seen in training. This understanding is necessary for researchers to determine whether to deploy a policy and assists them in debugging it, if necessary. It also enables end-users to decide whether to trust the robot.
Building understanding of black-box policies is thus a pressing open problem. We propose exposing observers to what the policy has learned, by showing examples of how it behaves in a variety of situations. A naive approach is to show the human how the robot acts in every possible state, but this is time-consuming, and infeasible for high-dimensional state spaces.
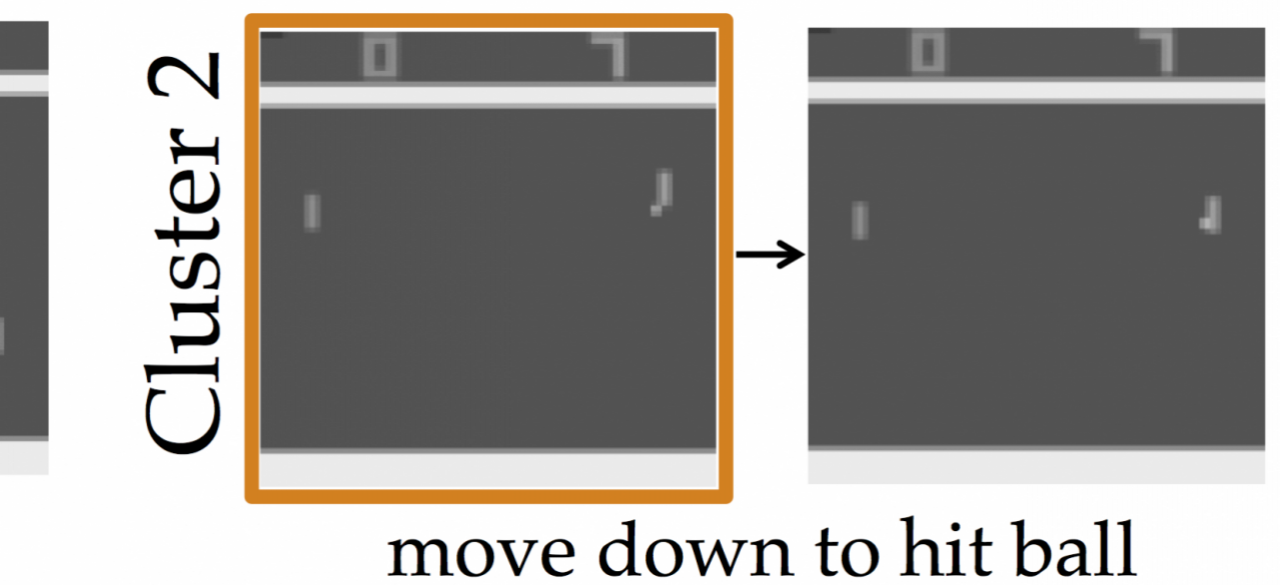
Our insight is that not all states are important. In other words, there are many states in which the outcome of the task is similar, regardless of which action the robot takes locally. But then there are a few states—critical states—where it really matters which action the robot takes. If the robot were to show us how it acts in these critical states, we would gain a better appreciation of the policy, and, if we agree with these actions, we would be more willing to deploy the robot.
We arrive at this insight by taking an algorithmic teaching [1] approach: the learner (a researcher or end-user) has an estimate of the robot’s policy, which she updates based on examples from the robot. The teacher (the robot) strives to provide examples that increase the person’s estimate of its performance. Our preliminary work suggests that the optimal teaching strategy is to show diverse critical states of the robot’s policy.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Anca Dragan | Sandy Huang | Debugging, Trust, Human Interaction |