Model-based Reinforcement Learning in a Latent Space
ABOUT THE PROJECT
At a glance
This project addresses the problem of generalizing from learning in simulated environments to the real world. Our approach is based on learning a latent representation of the state of the environment which carries information relevant to task goals but which is invariant to nuisance factors specific to the simulator. By design, the simulator and real world share the same task goals. Because the latent representation is free to discard information that is irrelevant to these goals we expect to see improved transfer between the simulator and the real world.
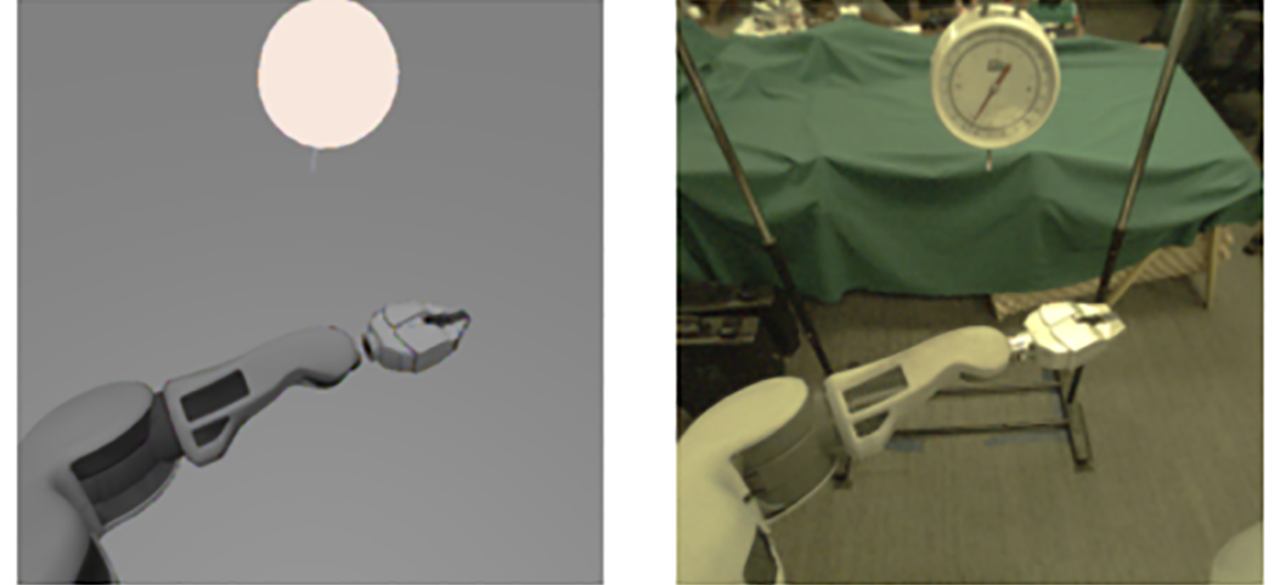
In transfer learning, we wish to transfer experience gained from training in an environment with a great deal of data (a simulated environment) to an environment with far less data (a real world environment). This is particularly important in robotics, where there are limited resources for gathering data in a real environment. Assuming that the simulation and real environment share the same task, we desire a model that can produce representations which are invariant to the extraneous differences between the simulated and real domains which are irrelevant to the target task. For example in the image below, the background and lighting conditions are significantly different in the simulation (left) and real (right) environment. But these differences are irrelevant to the task of grasping.
In light of these differences, standard model-based approaches where a model from actions to sensory input is learned in a simulated environment have little hope of transferring to the real world. Even doing this in the simulated domain is difficult, let alone having it transfer to the real domain. The high-dimensionality of the input and the complex representation of the dynamics make the modeling problem unnecessarily difficult when we are only after variables relevant to the task.
Here, we propose to generalize the approach of Jordan and Rumelhart to a latent state space rather than the original sensory input space provided by the environment. In our previous work (Agrawal et. al. 2016), we successfully extended Jordan and Rumelhart’s model to a learned latent state space. As shown in the figure below, a neural network is used to learn a mapping from image data I to a latent representation x. A forward model is then trained to predict x (rather than I) from actions. In the proposed project, we forego the need for an inverse model. Using the reward provided by the environment, we replace the inverse model with a critic model (Q function) to constrain the latent space. We argue that the simultaneous training of a latent dynamics model in conjunction with a provided reward will create a latent embedding sensitive to factors of variation relevant the reward signal and insensitive to extraneous factors of the simulated environment used during training.
The model will be tested and evaluated by comparing performance on simulated vs. real tasks performed by a PR2 robot, a quadcopter, and a remote-controlled model car. We expect to see a significant improvement in data efficient for training in the real task environment when the model is augmented with easily acquired simulated training data.
All code developed under this project to run the simulators used to train the model, as well as the underlying models which demonstrate the transfer from simulation to the real world, will be made available on the BDD code repository. Where applicable, real-world training datasets will also be provided.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Bruno Olshausen Sergey Levine | Brian Cheung Dinesh Jayaraman | Reinforcement Learning, Generalization, Simulation |