Robust Visual Understanding in Adversarial Environments
ABOUT THE PROJECT
At a glance
Machine learning, especially deep neural networks (DNNs), have enabled great progress in a variety of application areas. There is an increasing trend to apply deep learning to safety and security-sensitive applications, such as autonomous driving [1] and facial biometric authentication [6, 8]. For instance, vision system of a self-driving car can take advantage of DNNs to better recognize pedestrians, vehicles, and road signs, and make further decisions. However, recent research has shown that DNNs are vulnerable to adversarial examples: Adding small magnitude of carefully crafted adversarial perturbations to the inputs can mislead the target DNNs into misrecognizing them during run time [4, 9]. Such adversarial examples raise serious security and safety concerns when applying DNNs in real world applications. For example, PI’s previous research [2] has explored potential safety problems that adversarially perturbed road signs, say, STOP sign, could mislead the perceptual systems of an autonomous vehicle into misclassifying them into other speed limit sign with potentially catastrophic consequences. Thus, it is important to understand the security of deep learning in the presence of attackers and therefore develop defense strategies.
In this proposal, we propose a general framework to synthesize physical adversarial examples against various machine learning models, including classifiers, detectors, and segmentation methods, on different types of data, such as images and videos. Such physical adversarial perturbation should be robust in various viewpoints, and appear coherent with the main object. In addition, we also propose to develop defense strategies based on the understanding of adversarial examples in physical world. We propose to optimize neural networks with robust architecture for defense, and detecting adversarial examples based on both spatial or temporal consistency information. To further push forward the proposed physical adversarial example generation/defense strategies, we also propose to collect and synthesize real-world dataset under different driving conditions for in-depth analysis. In the end, we will contribute several physical adversarial example generation algorithms, and defense strategies to make the system more robust in the BDD Code Repository.
1 Physical Adversarial Examples
Given a wide variety of deep learning and machine learning algorithms applied in visual understanding, we will select some state-of-the- art algorithms to illustrate our preliminary results of attacking them, as well as proposed attack strategies.
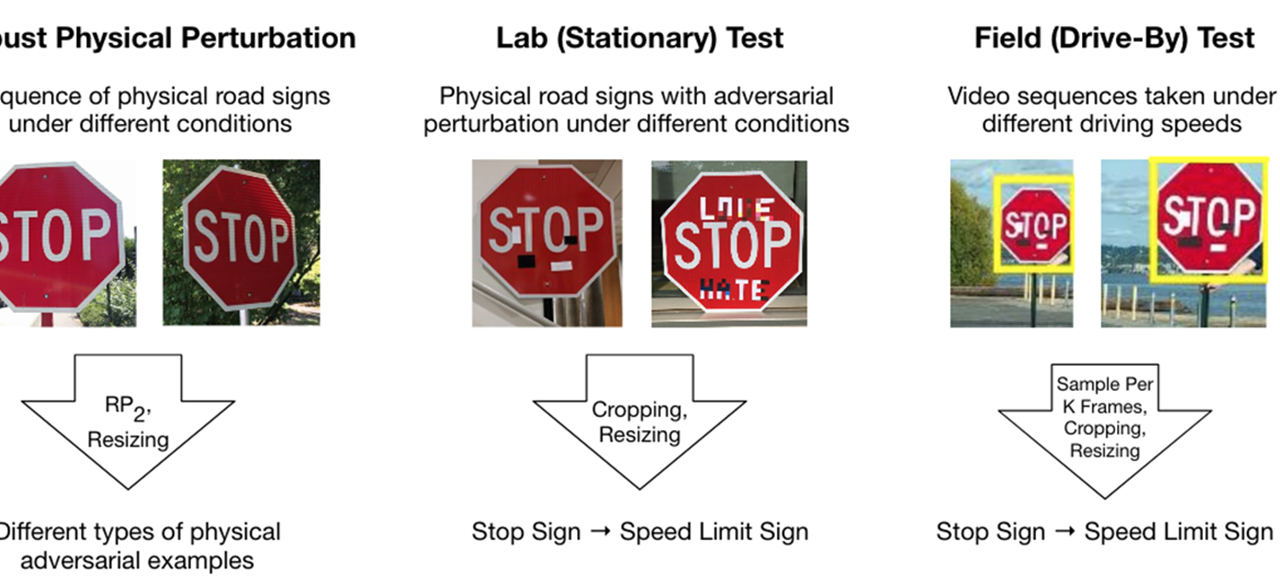
There are several challenges for generating adversarial examples in physical world. First, there are a lot of dynamic physical conditions, such as lighting, which may affect adversarial properties. Second, perturbation in physical world need to be content consistent, so that the physical perturbation can hide in human psyche. Third, current algorithms produce perturbations that occupy the background imagery of an object. It is difficult to create a robust attack with background modifications since a real object can have varying backgrounds depending on the viewpoint. Finally, actual fabrication process (e.g., printing) is imperfect and can cause issues in creating effective adversarial examples in the physical world. By solving these real-world challenges, PI’s recently work has shown that by adding printed color stickers on road signs, DNN based classifiers can be easily fooled by physical perturbations [2]. This is the first work to generate robust physical adversarial perturbation which remains effective under various conditions and viewpoints. A state-of-the-art classifier can misclassify a STOP sign as the target class, speed limit 45 sign, as shown in Figure 1.
Physical Adversarial Examples on Detectors Considering that detectors are commonly used in a lot of applications including vision systems of autonomous driving, generating adversarial examples in the physical world against detection models is important. In particular, detection algorithms have taken surrounding context into account when detecting certain objects, which makes generating adversarial examples even harder. We propose to generating physical adversarial examples against common detectors, such as YOLO [7] and Fast r-cnn [3]. In addition, we also propose to generate physical adversarial examples given black-box access to the models. For instance, we plan to apply ensemble attack against different models to realize physical targeted black-box attack, the effect of which has been validated in digital examples by PI’s previous research [5]. To generate robust physical perturbation under different physical conditions, we will sample transformations from general distribution, such as lighting and rotations, to optimize the perturbation (sticker). We also apply spatial constraints to realize spatially meaningful adversarial perturbation to make it less noticeable. The goal of physical adversarial examples against detectors can include: 1. make the target object disappear from detection results; 2. make the target object
Figure 1: Sample of physical adversarial examples against deep neural networks. All the STOP signs have been misclassified as speed limit 45 sign, and right turn signs misclassified as STOP sign. to be misrecognized as other targets. In addition to our proposed adversarial sticker perturbation, to satisfy goal 1, we can also generate “junk object” to put besides the target instead of being sticked on it. In detectors, different proposals are overlapped, such as YOLO, so adding one object can affect the detection result of the other nearby. Therefore, we propose to put, a poster or a 3D printed optimized adversarial “junk object” near our target, for instance, STOP sign, so as to make the sign disappear from the recognition system.
Physical Adversarial Examples on Segmentation Algorithms There has been work on generating digital adversarial examples for segmentation algorithms [11]. However, there are no physical adversarial examples that can fool standard segmentation algorithms yet. It would bring concerns if a 3D printed object on the road could cause autonomous driving cars to overlook other vehicles or pedestrians on the road. In order to understand this potential threat, we propose to synthesize a real world object, such as a pillar or a box, so that the object can cause segmentation algorithms to fail to correctly segment scenes containing the synthesized object. In order to produce unnoticeable perturbation, we propose to perform scene understanding first and synthesize object that are content coherent with surrounding environments.
Understanding Adversarial Examples Adversarial examples present intriguing properties. Here we propose to leverage feature inversion analysis to understand whether the misinterpreted features are closer to the target or just minimize certain distance metric without showing meaningful visualization. We also propose to explore good measurements for adversarial examples, which will help detect these examples. The PI’s prior work [12] has shown that the local intrinsic dimensionality can capture underlying properties for different data manifold. We propose to further investigate different measurements for separating adversarial examples. For instance, we can interpret instances to a unified latent space to measure activation of each layer to characterize adversarial behaviors for further detection.
2 Defending Against Adversarial Examples
With various adversarial examples against different visual understanding models, we propose to develop defense strategies to protect potential DNN based applications, such as autonomous driving.
Robust Architecture Optimization To defend against existing adversarial examples, we propose to design robust architectures of networks for visual understanding tasks. For instance, we plan to apply sparse networks by adding regularization in early layers to minimize the effects of adversarial perturbation. We also plan to apply deep reinforcement learning to optimize network structure based on the rewards (prediction accuracy) on our generated adversarial examples to improve network robustness.
Detection Based on Spatial Consistency In certain tasks, such as segmentation, the surrounding context is important for decision making. Therefore, we propose to break such context, aiming to destroy adversarial perturbation. For instance, within the segmentation task, we plan to train a separate network to segment patches randomly chosen from original images. During testing time, we can randomly select some patches and compare if the segmentation result of a patch is consistent with the the same patch within the segmentation result of the original image. Besides, we can also make use of the scale space theory to rescale/blur the original image and check if the segmentation result still remains the same, to detect whether adversarial perturbation has been added.
Detection Based on Temporal Consistency For real-world applications, especially autonomous driving, video is usually recorded Real world adversaries usually only have ability to insert adversarial perturbations in certain periods of the video due to the cost and accessibility of learning systems. Therefore, we propose to defend against such attacks based on the temporal consistency of video data. For instance, we plan to apply different temporal based features, such as optic flow of the video to perform segmentation. Then, we will apply these trained segmentation models as ensemble models to check the consistency of results. This way, the temporal information is captured, and adversarial perturbations can be detected if the segmentation results from different models deviate too much.
3 Dataset For Robust Visual Understanding
We plan to utilize BDD diverse driving video database to conduct this investigation. There are currently 100K videos with annotations on the key frames in the database. Three types of annotations are most relevant to our study: object bounding detection, drivable area and full-frame segmentation. The object detection is labeled by bounding boxes and its categories include various types of vehicles, pedestrians, traffic signs, and traffic lights, which are necessary signals for the driving decisions. These data and annotations can be directly used for our investigation of defense with spatial and temporal consistency for object detection and segmentation problems.
In addition, we propose to build up a standard benchmark for defending against adversarial perturbation. Given each video in the database, we will conduct robust attacks that are invariant to different data transformation and training procedures and transform the testing data based on the attacking results. This benchmark can be used to evaluated the model robustness and stimulate future research in model defense. This proposed research will increase the impact of the BDD video database and bring the data to a broader community.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Dawn Song, Trevor Darrell | Bo Li, Fisher Yu | Physical Adversarial Example, Machine Learning, Security, Autonomous Driving |