Explainable Deep Vehicle Control and User-Defined Constraints
ABOUT THE PROJECT
At a glance
This proposal covers two related topics: (i) textual explanations of vehicle controller actions and (ii) human specification of constraints on the control policy. This will build on our work that appeared at ICCV 2017 [1] and NIPS 2017 [2]. Deep networks have shown promise for end-to-end control of self- driving vehicles [3], but such networks are quite cryptic. There are no interpretable states or labels in such a network, and representations are fully distributed as sets of activations. Explanations can be either rationalizations – explanations not grounded in the system’s behavior, or causal explanations – explanations that are based on the system’s internal state, and which ideally represent causal relationships between the system’s input and its behavior. Our work focuses on causal explanations, in order to help users better understand and anticipate the system’s behavior.
Visual Explanations
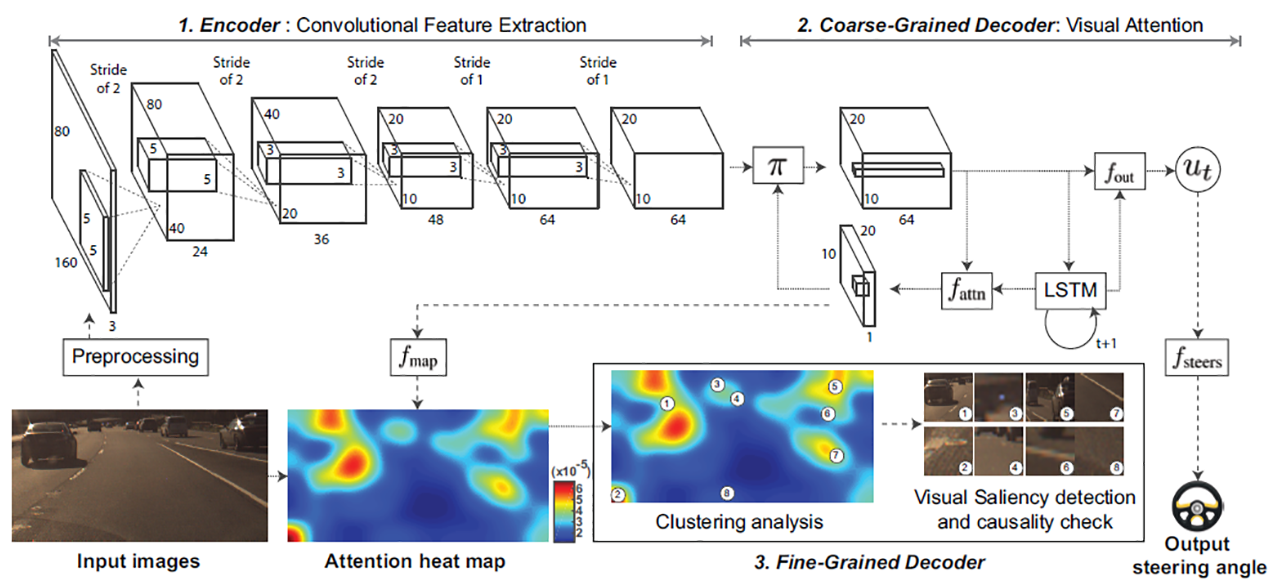
Our first approach was presented in [1]. It uses an attention model integrated with an end-to-end vehicle controller with camera input. The attention model highlights areas of the image that are potentially salient for the vehicle’s behavior. We add a causal filtering layer to remove regions of attention that are not actually salient, leading to a less cluttered and more interpretable visualization. The controller and sample output are shown below: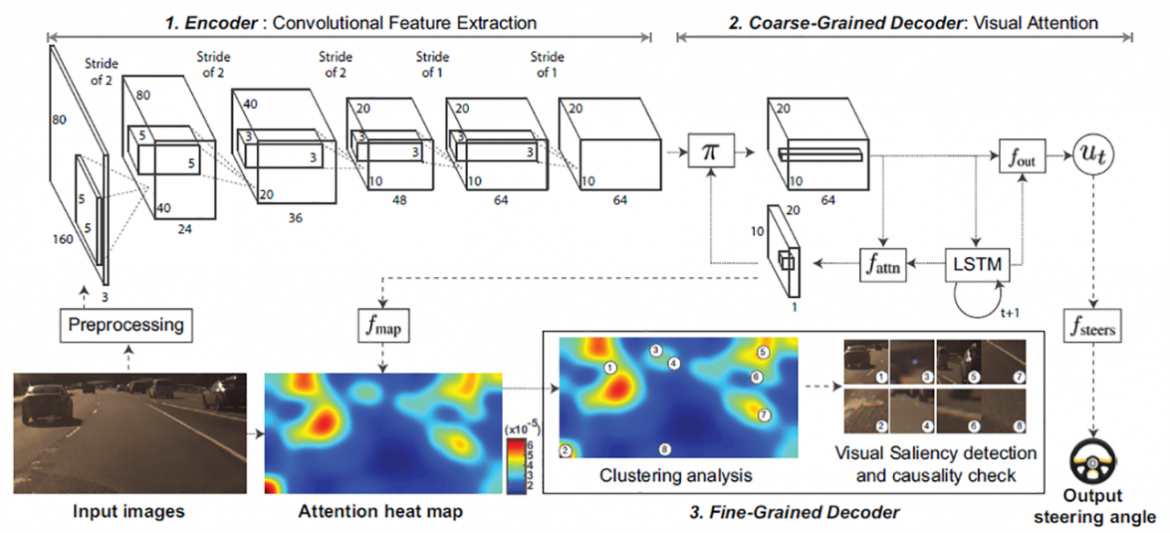
Textual Explanations
Our most recent work is focused on generating textual descriptions + explanations, such as the pair: “vehicle slows down” and “because its approaching an intersection and the light is red”. In order to train such a model, we use a dataset collected by BDD of explanations generated by human annotators. This explanation dataset is built on top of another BDD dataset collected from dashboard cameras in human- driven vehicles. Annotators (who view the first video dataset but are not in the vehicle) compose explanations for the behavior that the vehicle driver made. These explanations are rationalizations, and so are useful for training human-sounding explanations, but provide no grounding of these explanations in the vehicle controller’s behavior. In order to ground the explanations, we use the same visual attention model described earlier for the vehicle controller. We also use a spatio-temporal attention model for the explanation generator. This latter model highlights image areas that are salient for the explanation. That is, it will highlight areas such as traffic lights while producing the word sequence “traffic lights”. We use a loss between the two attention maps which makes it likely that the explanation refers to the objects that were actually salient to the vehicle’s behavior. The design is shown below: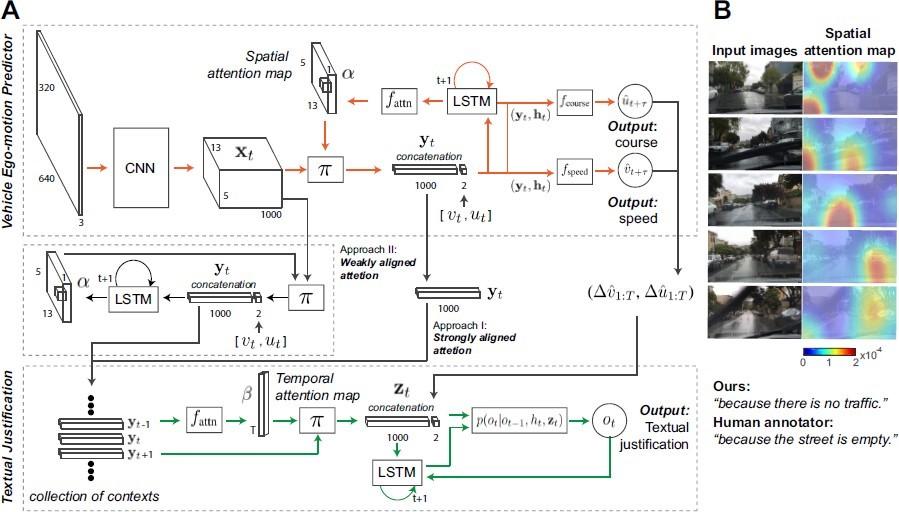
Proposed Work
This project will extend our prior work on explanations but add a focus on user constraints, such as “always stop completely at stop signs”. Imperatives will be transformed into condition-action pairs using the lexicon already trained as part of the vehicles description/explanation system. Condition-action pairs generate a loss (act as a critic) whenever the implication is violated i.e. “vehicle is at a stop sign” and not “vehicle stopping”. These loss terms will be added to the control loss during training in order for the system to learn to enforce the constraint (whether or not users enact that behavior).
References
1. Jinkyu Kim, John Canny, Interpretable Learning for Self-Driving Cars by Visualizing Causal Attention, ICCV 2017
2. Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata, Show, Attend, Control, and Justify: Interpretable Learning for Self-Driving Cars, NIPS Symposium on Interpretable Deep Learning, 2017.
3. M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, et al. End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316, 2016.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| John Canny | self-driving vehicles, explainable models, neural networks, imitation learning, attention models, deep networks, sequence models |