Training and Hardware-Software Co-design for Implementation of Small- Footprint Neural Networks
ABOUT THE PROJECT
At a glance
During the BDD 2017 funding period we developed methods and tools for tailoring the compression and execution of the Deep Neural Networks (DNN) to the underlying hardware architecture. We demonstrated this methodology through structured pruning of fully connected layers and implementation techniques that efficiently leverage the resulting computation patterns on modern mobile and embedded GPUs.
Due to great diversity of embedded devices, DNN designers have to take into account the hardware platform and application requirements during network training. Our work introduces pruning via matrix pivoting as a way to improve both the performance and accuracy of pruned networks by compromising between the accuracy and design flexibility of architecture-oblivious, and performance-efficiency of architecture-aware pruning, the two dominant techniques for obtaining resource-efficient DNNs. We also described local and global network optimization techniques for efficient implementation of the resulting pruned networks.
In combination, the proposed pruning and implementation result in close to linear speed-up with the reduction of network coefficients during pruning.
- The details of developed methods and performance benchmarks of our approach against vendor libraries can be found in our paper “Structured Deep Neural Network Pruning via Matrix Pivoting”, currently under review and available on arXiv1.
- The tools, examples and documentation can be found in bdd2 repository under isg subdirectory.
For the next funding period we propose the following extensions of this work:
1) Further development of implementation tools and training methods to enrich the portfolio of algorithms and network implementations of interest to BDD. Specifically, we plan to:
- Add coefficient quantization during training to our pruning tools;
- Improve training efficiency when structured pruning is applied and perform accuracy/pruning tradeoff experiments on several network topologies of interest;
- Expand the pruning algorithm to include larger data sets and networks such as ImageNet
- Apply our pruning techniques to non-classification problems, such as various regression-based DNNs
- Evaluate our algorithm on recursive neural networks and outline the compression and performance enhancement tradeoffs
2) Study the speedup and performance potentials at the training phase with the pruning techniques and the parameters characterization
- Distributed computing platform analysis and performance impacts with multiprocessor systems and its consequent usage
- Algorithmic optimization for error analysis and system coefficients
Research overview and continuing research plan
Despite all recent progress, leveraging Deep Learning on mobile and embedded platform remains a significant challenge. Reducing the memory/compute footprint of DNN models and efficient scheduling are the most promising directions to addressing it.
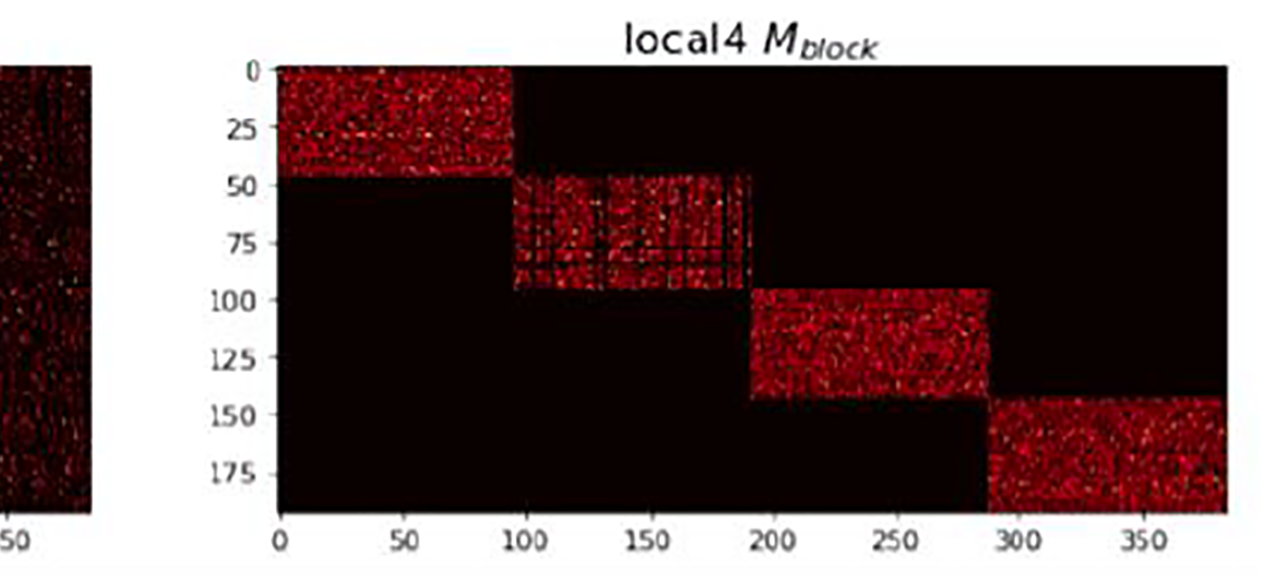
Many attempts at this work have been made so far in a top-down manner, by changing the DNN architecture and training according to hints from proxy metrics such as operation and coefficient counts. Unfortunately, proxy-based approaches deliver improved performance with a deep discount relative to the decrease of the network capacity and increase in training complexity. For example, Baidu Research2 recently reported their performance benchmarks when pruning large language translation networks, specifically pointing out that unstructured sparsity decreases computation efficiency of modern GPUs and results in significant gaps between coefficient reduction and inference latency reduction We take the bottom-up approach to this problem, by first looking into what kind of computing patterns are well matched to modern CPU/GPU architectures. Then we impose training constraints that incentivize such structures, while aiming to maintain similar test accuracy. In this work we realized that having regular memory access patterns and well balanced computation load between parallel processing elements is at least as important as reducing the number of network weights for both latency and power reduction. Hence, we devised a strategy to ensure good load balancing and well aligned memory access when training sparse layers.
By training in this way we guarantee good cache performance despite the fact that the matrix is sparse, unlike most previous attempts. Furthermore, our approach enables the flexibility in adapting the scheduling of the compressed layers to the underlying architecture, as we demonstrate on the Arm Mali and NVIDIA Jetson examples shown below, where we maintain close to linear speed-up with compression ratio on two very different GPU architectures. A more detailed performance comparison with standard sparse and dense linear algebra operators can be found in our paper.
Finally, the training seems to preserve or incur only marginal penalty in classification accuracy when imposing this constraint, as tested on CIFAR-10 dataset. In the next phase of the project we plan to expand this approach to both larger data-sets and a variety of other network topologies of interest to BDD.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Vladimir Stojanovic | Ranko Sredojevic , Lazar Supic, and Rawan Naous | Hardware-software codesign, architecture, compression, memory, embedded, inference, detection |