From Optimization to Sampling: Efficient Methods for Inference With High-Dimensional Distributions
ABOUT THE PROJECT
At a glance
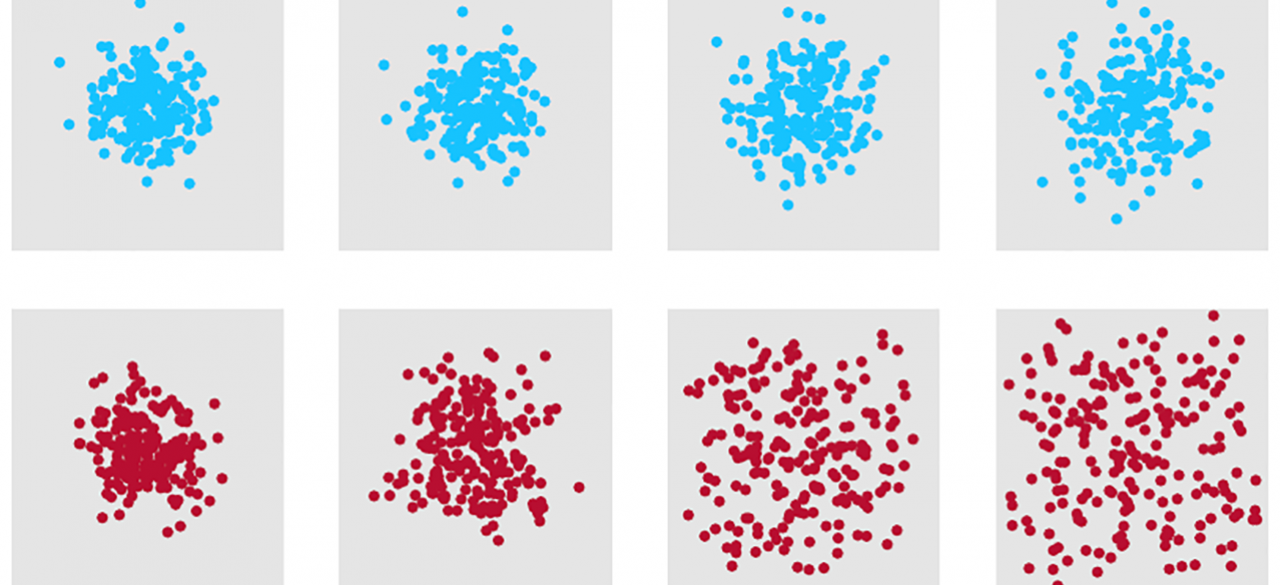
A core problem in statistical machine learning is that of drawing samples efficiently from a high-dimensional distribution. Effective algorithms for sampling are broadly useful. First, when building prediction rules via boosted regression trees or neural networks, sampling methods are needed for evaluating the stability and robustness of learned models. As a second example, sampling is required for approximate dynamic programming, stochastic control, and reinforcement learning, where it is used to construct scenario trees and perform roll-out. Third, sampling methods are useful for exploring the posterior distribution in Bayesian models, and for generating textures and other objects in computer vision.
While the sampling problem is easily stated, it is notoriously difficult in high dimensions, and the goal of this work is to tackle this challenge. There are two main components to the proposed work:
• development and analysis of sampling algorithms based on discretizations of stochastic differential equations (SDEs), with the Langevin diffusion (described below) being a special case
• exploration of methods for assessing the accuracy of sampling algorithms based on Stein discrepancy, and other methods from optimal transport.
| principal investigtors | researchers | themes |
|---|---|---|
| Martin Wainwright | Raaz Dwivedi and Wenlong Mou | advanced machine learning, high-dimensional sampling, efficient algorithms, un- certainty analysis and robustness |