Time-Series LIDAR and Camera Fusion with Structured Variational Inference
ABOUT THE PROJECT
At a glance
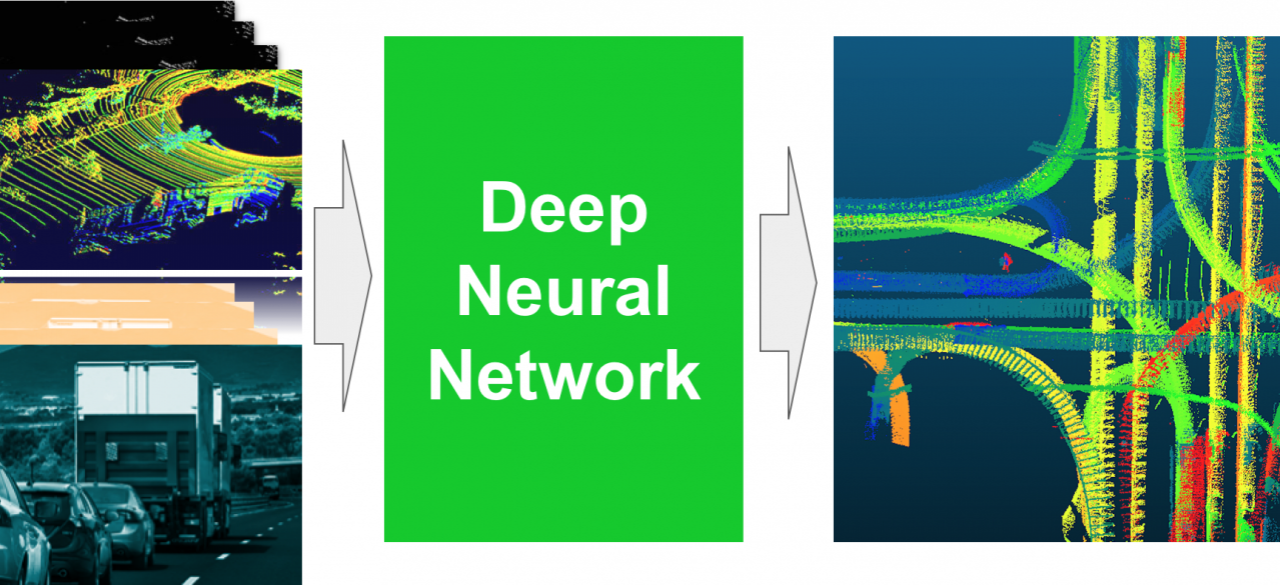
Single-frame-based methods for LIDAR and camera fusion have been widely explored and developed in the last two years with significantly improved accuracy for 3D object detections. However, the multi-frame time-series information in historical data was not well exploited in deep neural networks (DNN) for sensor fusion. In fact, introducing time series has great potential in increasing the accuracy of not only 3D detection, but also tracking and prediction with properly designed association. Moreover, the consistent features from different sensors in multiple frames make it possible to overcome the spatial and temporal mismatch of different sensors in a single frame caused by the errors in calibration and synchronization. Therefore, we propose to introduce time-series data into the camera and LIDAR fusion network. In order to enhance the interpretability of the fusion and incorporate the domain knowledge, we propose a structured variational inference architecture for the combination of the flexible deep learning method and structured Bayesian priors.
Challenges and Technical Approach
There are several technical challenges in time-series camera and LIDAR fusion.
(1) Constructing interpretable dynamical structure to the network while keeping the training pipeline end-to-end. Recurrent neural network (RNN) is commonly used to process time-series data. However, the state space of RNN is usually very high-dimensional and the network is not interpretable. The variational autoencoder (VAE) is well-known to be capable of encoding high-dimensional observations to low-dimensional latent variables. Dynamics of low-dimensional states can be propagated through probabilistic graphical models (PGM) to utilize Bayesian priors such as dynamic models and finite state machines. Instead of RNN, the whole architecture becomes an observer with structured low-dimensional dynamics and normal DNN. The training of the whole architecture is addressed by some previous work such as Deep Kalman Filter and structured variational inference algorithms.
(2) Introducing the spatial context information extracted from LIDAR and high-definition (HD) map to the network. For the PGM utilizing Bayesian priors such as dynamic models and finite state machines, separated manifolds for different scenarios need to be constructed from spatial context information. We propose to employ a manual supervision on the context by splitting its behavior into manifolds indexed by the context.
(3) Modeling PGM that is tractable to learn flexible representation in order to deal with various situations. PGM is powerful for building structured representation and efficient inference. However, it often relies on rigid assumptions which makes it not suitable for inferencing in high-dimensional space. Algorithms for PGM such as message passing or junction theories will be investigated to find the most appropriate model that can fully exploit the power of PGM.
Related Prior Work
(1) With the last year’s effort in this project, approaches for 3D object detection based on camera and LIDAR fusion were proposed by our research group. The sparse non-homogeneous pooling layer was developed to efficiently fuse the whole camera and LIDAR feature maps from different views. Various kinds of one-stage detection networks based on YOLO and RetinaNet were designed and tested with simpler structure and faster speed than other fusion-based networks. The 3D localization performance was of the highest tier on KITTI dataset.
(2) A method to handle a traffic-light-passing scenario was designed based on hierarchical reinforcement learning (HRL). Further research introduced a supervision method that splits the behavior into manifolds indexed by the context, while normal training learns a uniform pattern of behavior regardless of different context information.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Masayoshi Tomizuka | Wei Zhan, Zining Wang and Kiwoo Shin | sensor fusion, time series, structured variational inference |