Learning Human-Like Decision-making Behavior based on Adversarial Inverse Reinforcement Learning
ABOUT THE PROJECT
At a glance
Background
The project title has been revised from the original “Learning Human-Like Driving Behavior via Augmented Reward and Data” to “Learning Human-Like Decision-making Behavior based on Adversarial Inverse Reinforcement Learning” to better reflect the work carried out under this project.
This research work described herein, titled “Learning Human-Like Decision-making Behavior based on Adversarial Inverse Reinforcement Learning”, is jointly proposed by Dr. Pin Wang, Dr. Ching-Yao and Prof. Sergey Levine under BDD in 2019.
Problem Statement
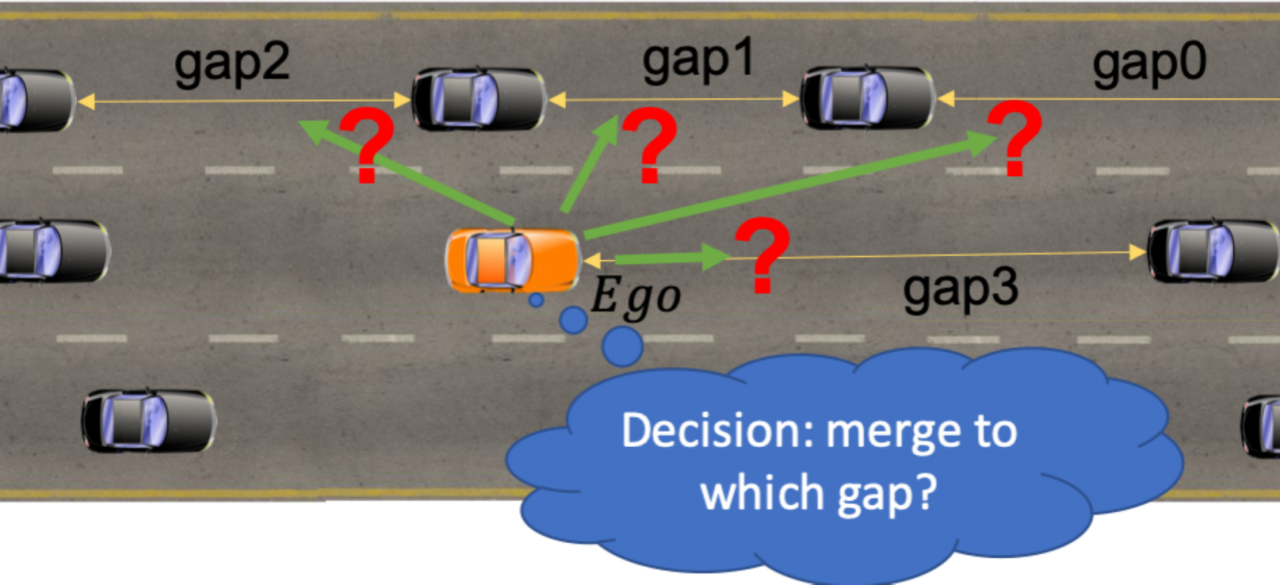
Reinforcement learning (RL) provides an appealing option for learning autonomously controllers. However, RL relies critically on access to a good reward function, which specifies which behaviors are desirable and undesirable. Learning reward functions from demonstrations (e.g. Inverse Reinforcement Learning, IRL) offers a good way of making good use of naturalistic human driving data. However, because of the expansive reinforcement learning procedure in the inner loop, it has limited application in problems involving high-dimensional state and action spaces. Combining generative adversarial learning and IRL is an emerging direction to efficiently learn time-sequential strategies from demonstrations. Generative Adversarial Imitation Learning (GAIL) combines Generative Adversarial Network with Imitation Learning and learns a policy against a discriminator that tries to distinguish learnt actions from expert actions. Adversarial Inverse Reinforcement Learning (AIRL) is similar to GAIL but also learns a reward function at the same time and has better training stability.
The applications of these methods (e.g. GAIL, AIRL) are mostly verified with control tasks in OpenAI Gym. However, autonomous driving is a complicated problem as it involves extensive interactions with other vehicles in a dynamically changing environment, and this is particularly true for the decision-making task that needs to monitor the environment and decides maneuvering commands to be issued to the control module. In this study, we apply AIRL to learn the challenging decision-making behavior in a simulated environment where each vehicle is interacting with all other vehicles in its surroundings. Our study, different from RL based studies, makes good use of demonstration data and, different from IRL based studies, learns both a reward function and a policy.
Additionally, we augment AIRL with some intuitive semantic reward to assist learning. In the original AIRL formulation, the reward function is formulated purely in the view of the adversarial learning theory and learned from demonstrations via neural networks. If we can provide the agent some domain knowledge about the task with a semantic but sparse reward signal, it should assist it to learn fast and effectively. Based on this insight, we augment the learned reward function with intuitively defined semantic reward term.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
Human-Like Driving Behavior, Reinforcement Learning, Imitation Learning, Inverse Reinforcement Learning, Augmented Reward and Data |