Adversarial Examples in Reinforcement Learning and Imitation Learning
ABOUT THE PROJECT
At a glance
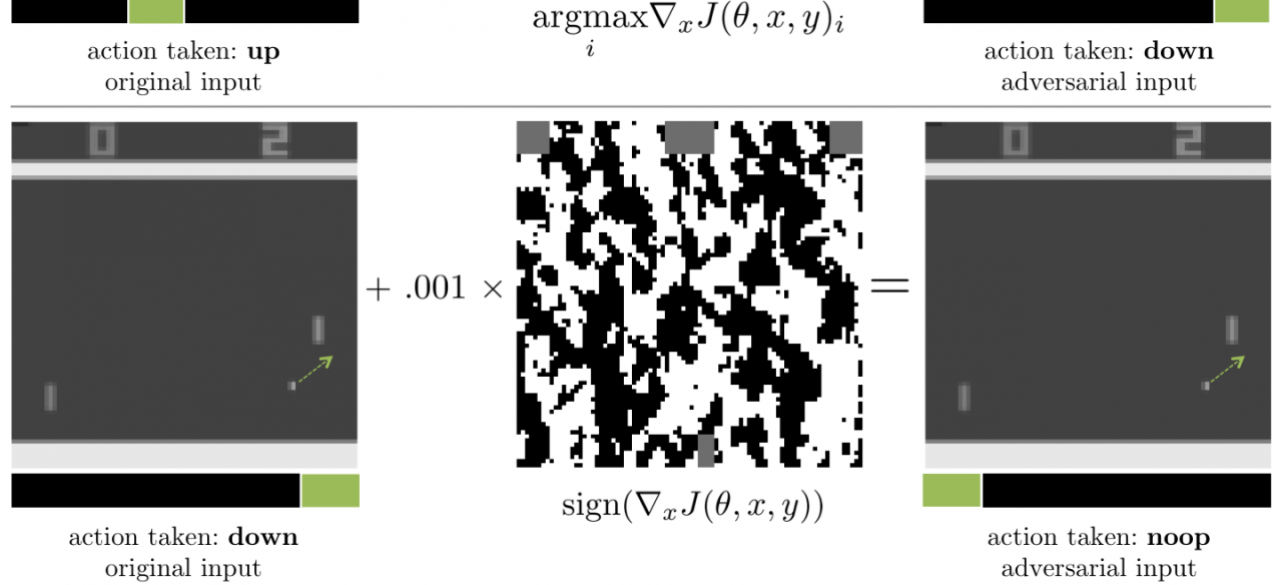
It has been found that deep neural net classifiers (as well as many other classifiers) are highly vulnerable to adversarial examples. An adversarial example is a sample of input data which has been modified very slightly in a way that is intended to cause a machine learning classifier to misclassify it. In many cases, these modifications can be so subtle that a human observer does not even notice the modification at all, yet the classifier still makes a mistake. Adversarial examples pose security concerns because they could be used to perform an attack on machine learning systems, even if the adversary has no access to the underlying model. This includes attacks in the real world by, for example, making tiny modifications to traffic signs. In reinforcement and imitation learning, AI systems are supposed to choose actions over time to pursue prescribed objectives (e.g., driving home safely, setting the table, manufacturing a widget, etc). Since these systems get to act, it is even more critical to understand susceptibility to adversarial examples, and how to guard against them. Indeed, it might be the case that well-chosen adversarial examples can make an AI system optimize for a completely different and undesired objective.
We are seeking to develop an understanding of susceptibility to adversarial examples in deep reinforcement learning and deep imitation learning. This includes white box settings where the adversary has access to the learned control policy as well as black box settings where the adversary doesn’t have access to the learned policy, but only gets to observe traces and/or a limited number of interactions with the environment and learned policy.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Pieter Abbeel | Sandy Huang |