Fusion of Deep Convolutional Neural Networks for Semantic Segmentation and Object Detection
ABOUT THE PROJECT
At a glance
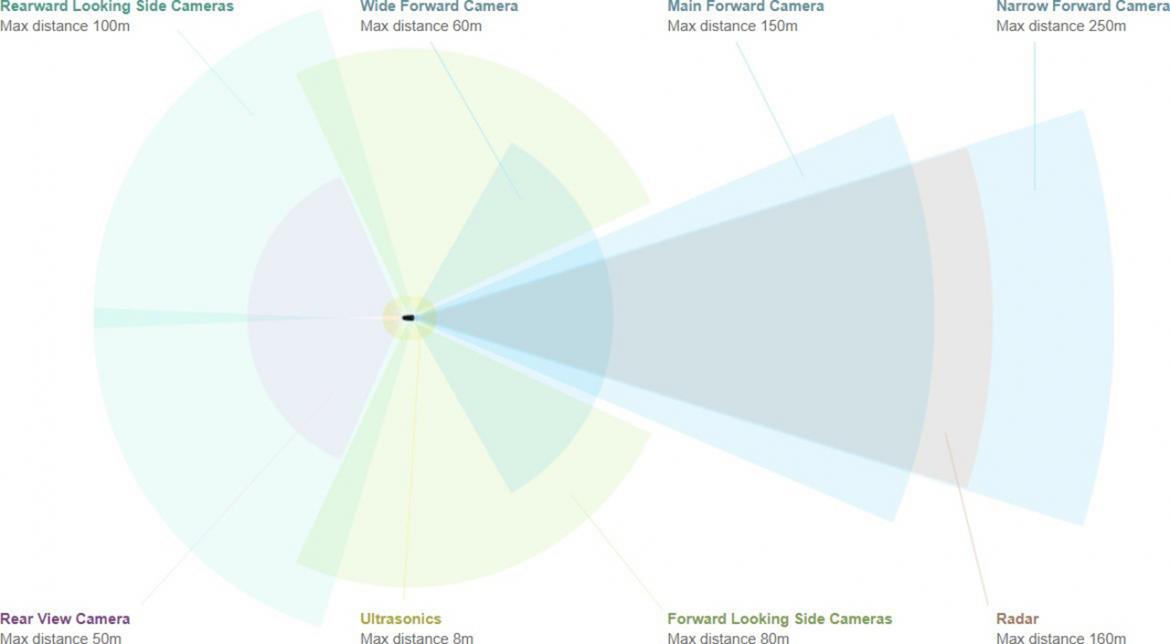
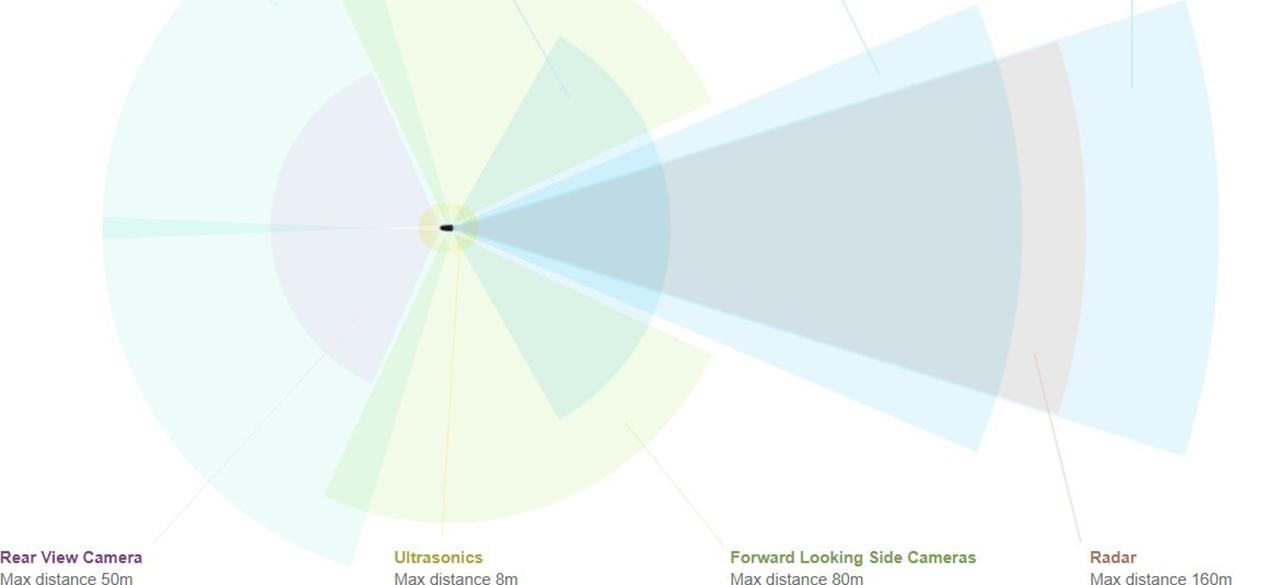
Figure 1: An example of sensors used in a typical driverless car.
Sensor fusion is an important part of all autonomous driving systems both for navigation and obstacle avoidance. Figure 1 shows an example of the sensors used in a typical driverless car inlcuding multiple cameras, radar, ultasound, and LiDAR. While deep learning algorithms have been investigated for semantic segmentation of images from a single RGB camera or a RGBD cameras, or Lidar, application of deep learning to multiple modality sensors is not well understood. In this work we will investigate deep learning architectures for fusion of multimodal sensors resulting in 3D point cloud, RGB images, and other signals.
Fusion is widely used in signal processing domains and can occur at many different processing stages between the raw signal data and the final information output. Fusion in signal processing can be broadly characterized as happening at one of three levels: raw signal (input), generated features (intermediate processing), or information (output). Raw signal fusion is typically the domain of multimodality research when the modalities share, or map to, a common structure. Sensor fusion is a common technique in signal processing to combine data from various sensors, such as using the Kalman filter. Gross et al. [5] used the Kalman filter to fuse various aircraft sensors in order to determine the altitude of an aircraft. Feature fusion is also common, ranging from simple concatenation to advanced methods such as fuzzy integrals. For example, Penatti et al. [6] extracted features from the CaffeNet and OverFeat DCNN and then concatenated them as the input to an SVM. Finally, information fusion combines independent results from signal processing techniques that could otherwise be used alone as the final signal processing result. For example, Waske and Benediktsson [7] fused SVM trained on synthetic aperture radar data and multispectral data.
Prior work: In prior work [4] , we proposed a semantic segmentation algorithm which effectively fused information from images and 3D point clouds. The method incorporated information from multiple scales in an intuitive and effective manner. A late-fusion architecture was used to maximally leverage the training data in each modality. Finally, a pairwise Conditional Random Field (CRF) was used as a post-processing step to enforce spatial consistency in the structured prediction. The algorithm was evaluated on the publicly available KITTI dataset [1] [2], augmented with additional pixel and point-wise semantic labels for building, sky, road, vegetation, sidewalk, car, pedestrian, cyclist, sign/pole, and fence regions. A per-pixel accuracy of 89.3% and average class accuracy of 65.4% is achieved, well above current state-of-the-art [3]. The block diagram of our approach in [4] is shown in Figure 2.
Proposed Work: In this project we will investigate optimal architectures for fusing multi-modal signals typically used in autonomous driving, namely 3D point clouds and RGB pictures. In particular, we will investigate late or early fusion architectures as shown in Figure 2, and determine whether fusion at raw level, feature level, or information level is most appropriate for object detection, obstacle avoidance, and semantic segmentation. We will approach this in two phases: in phase 1 we experiment with data from autonomous systems indoors and in phase 2 we migrate to outdoor data for autonomous driving.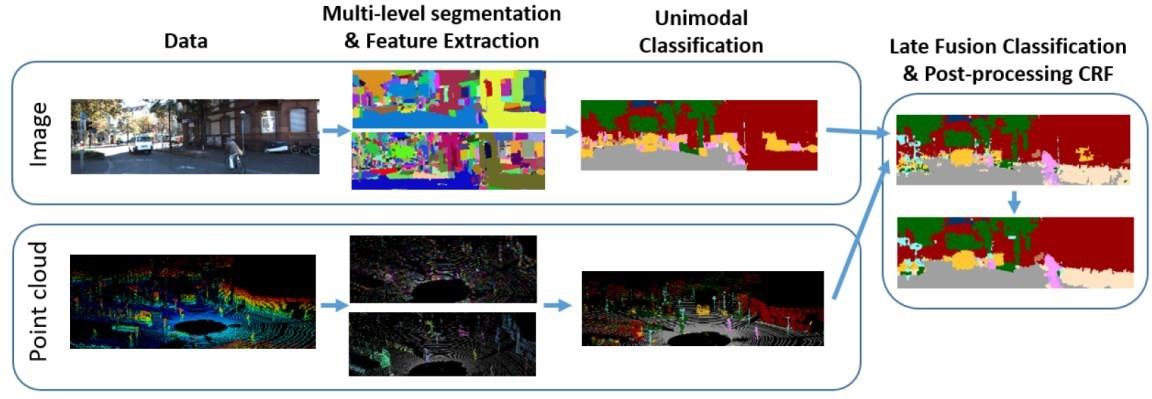
Figure 2: Pipeline for prior work in [4].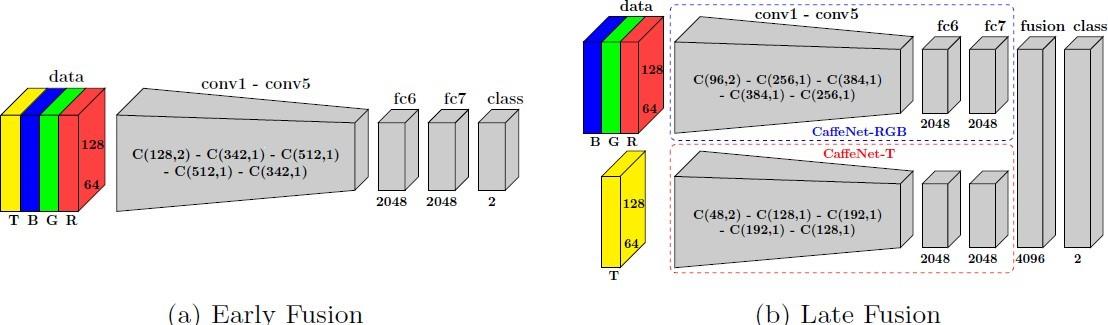
Figure 3: Examples of early and late deep fusion using neural networks.
References:
- A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,” 2013.
- A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in CVPR, 2012.
- C. Cadena and J. Kosecka, “Semantic segmentation with heterogeneous sensor coverages,” in ICRA, 2014.
- R. Zhang, S. A. Candra, K. Vetter, and A. Zakhor, "Sensor Fusion for Semantic Segmentation of Urban Scenes." IEEE International Conference on Robotics and Automation (ICRA), Seattle, Washington, May 26th-30th, 2015.
- J. N. Gross, Y. Gu, M. B. Rhudy, S. Gururajan, and M. R. Napolitano, “Flight-test evaluation of sensor fusion algorithms for attitude estimation,” IEEE Trans. Aerosp. Electron. Syst., vol. 48, no. 3, pp. 2128–2139, Jul. 2012.
- O. A. B. Penatti, K. Nogueira, and J. A. dos Santos, “Do deep features generalize from everyday objects to remote sensing and aerial scenes domains?” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Jun. 2015, pp. 44–51.
- B. Waske and J. A. Benediktsson, “Fusion of support vector machines for classification of multisensor data,” IEEE Trans. Geosci. Remote Sens., vol. 45, no. 12, pp. 3858–3866, Dec. 2007
| principal investigators | researchers | themes |
|---|---|---|
| Avideh Zakhor | Matthew Tancik | fusion, deep neural networks, multi-modal |