Implementing and Evaluating Second-Order Optimization for Deep Learning on Diverse Architectures
ABOUT THE PROJECT
At a glance
First-order optimization methods—e.g., SGD and its variants—are ubiquitous, but they come with well-known deficiencies that second-order methods easily solve. Second-order methods use second derivative and not just first derivative information, and so they tend to be more expensive. Recent work has begun to consider the use of second-order methods for deep learning and other ML problems. A challenge is that developing high-quality implementations can be non-trivial, in part since second-order methods can be more sensitive to architectural issues than simpler first-order methods. The time is ripe for a thorough reevaluation of these methods. Of particular interest is the use of trust region (TR) and cubic regularization (CR) versions of these methods in models with non-convex loss functions. Such models are ubiquitous: multi-layer neural networks; discriminative training of mixture models; models such as latent factor models with “products” of parameters; etc. Our goal will be twofold: first, to provide a detailed implementation in different architectures of recently-developed scalable second-order optimization methods; and second, to provide a detailed evaulation of them in non-convex deep learning problems of interest for the BDD project.
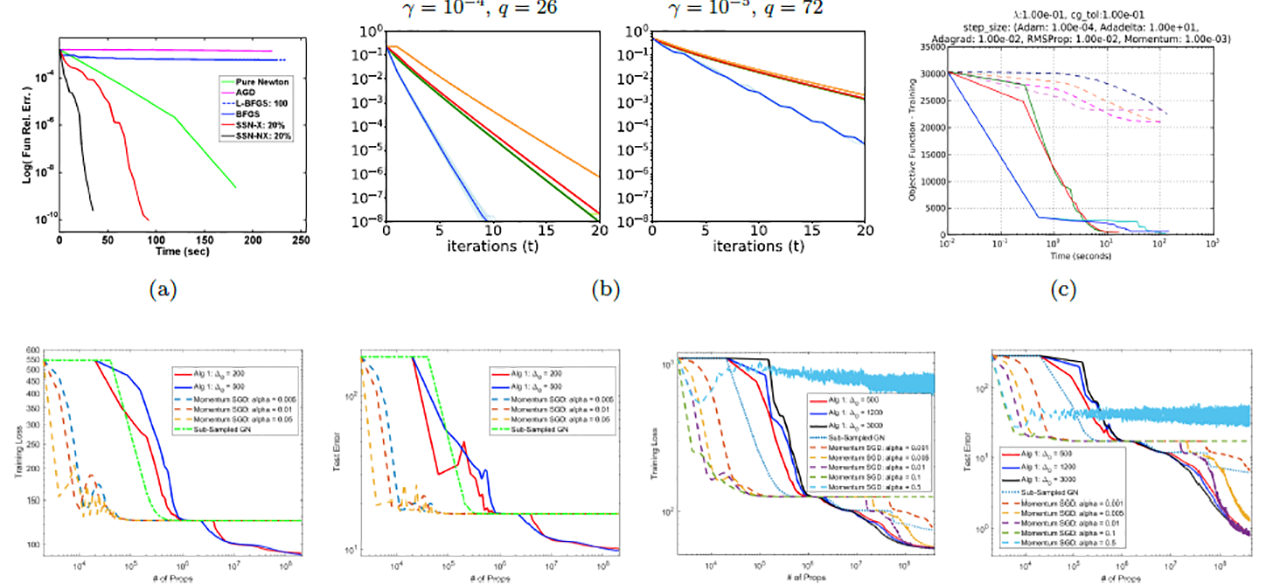
Prior work. In prior work, we have a proof-of-principle treatment of sketching as a way to reduce compu- tational complexity of Newton-type methods, for both convex and non-convex problems, in both RAM and parallel environments, and with both CPUs and GPUs; see [5, 6, 7, 8, 9] and references therein. We considered convex problems and characterized thoroughly the local and global convergence properties of sub-sampled Newton methods, where the gradient and/or the Hessian are uniformly or non-uniformly sub-sampled [5, 6]. We employed similar ideas for TR and CR algorithms for non-convex optimization [8] and presented initial empirical results illustrating the practical usefulness of these methods for non-convex ML problems [9]. We also considered distributed variants of sub-sampled Newton methods that are highly suitable for distributed settings, in which communication across the network is the major bottleneck [7]. In contrast to popular first-order algorithms, we empirically demonstrated the robustness of Newton-type methods to the choice of hyper-parameters [9] and showcased their resilience properties to ill-conditioning [5, 6]. In (unpublished) work-in-progress, we have also shown that by leveraging resources such as GPUs, Newton-type methods can be made computationally highly favorable to many first-order alternatives available as part of popular ML software packages, such as TensorFlow [3]. See Figure 1 (and [5, 9, 7] for details on the models, loss functions, data/applications, etc.) for examples of promising prior work.
Work description. We will focus on two main directions. In each case, we will be interested in two main goals: demonstrating competitive/superior performance, relative to first order methods, for BDD-type appli- cations; and demonstrating scalability in parallel implementations, in different computational environments, e.g., in Alchemist [2] and Ray [1] in the RISELab stack, with and without access to GPUs.
Sketched negative-curvature methods for non-convex ML problems. Until recently, the majority of effort in designing efficient second-order algorithms has focused on convex problems [5, 6]. However, now there is a surge of interest in designing second-order methods for the non-convex setting. In recent work [8, 9], we have studied, both theoretically and empirically, sub-sampling schemes for classical TR methods as well as CR for solving large-scale non-convex finite-sum problems. In this project, we intend to extend the parallel matrix approximation approaches from randomized numerical linear algebra (RandNLA) [4] to negative cur- vature direction methods for arbitrary, i.e., not necessarily finite-sum, non-convex problems.
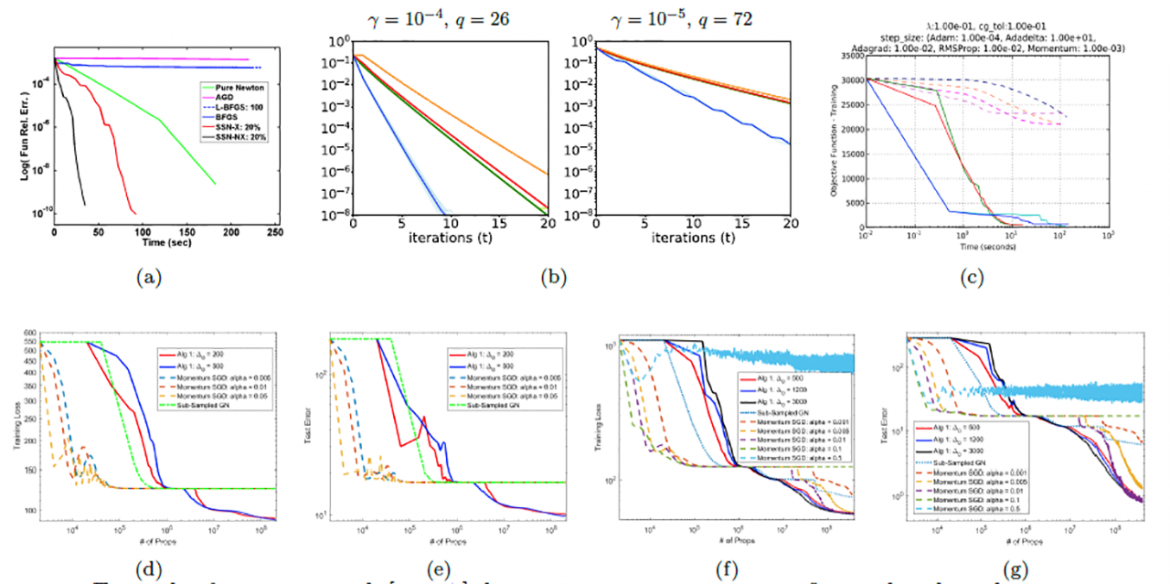
Figure 1: Examples from prior work [5, 9, 7] demonstrating, in contrast to first-order algorithms, attractive features of Newton-type methods: resiliency to problem ill-conditioning (1(a)), low-communication costs in distributed settings (1(b)), computational advantages from GPUs (1(c)), ability to escape undesirable saddle- points (1(d),1(e)), and good generalization error and robustness to hyper-parameter tuning (1(f),1(g)).
In particular, we will study stochastic variants of Gill-Murray Stable Newton’s method, the Fiacco-McCormick method, and the Fletcher-Freeman method (details in the Nocedal-Wright book), where we will incorporate RandNLA sketching tools to accelerate the matrix decompositions involved. Based on our previous experience [8, 9], we believe that only a rough sketch of the corresponding Hessian matrix would be sufficient to obtain prov- ably convergent algorithms with desirable empirical properties. The main technical challenges here involve sketching the potentially indefinite matrices and characterizing the convergence behavior of such stochastic methods, e.g., to saddle points or local minima, which can significantly impact downstream ML applications.
RandNLA to speed up TR sub-problem solver. TR methods are considered as alternatives to line- search techniques, as they define a region around the current iterate within which they trust the model to be a reasonable approximation, and they then find the step as a (approximate) minimizer of the model in this region. The computational bottleneck in TR algorithms is the minimization of the constrained quadratic sub-problems, and the connections between the TR problem and eigenvalue problems suggest that more efficient TR algorithms should exist. In [8, 9], we considered sub-sampling variants of the classical TR algorithm where the Hessian in the sub-problem is replaced with its sub-sampled approximation. We then employed some black box sub-problem solver for approximately solving the sub-problem. In this project, we aim to open these black box solvers and employ powerful parallel ideas from RandNLA and low rank matrix approximation to improve upon their efficiency in solving the sub-problem.
Data policy. We will make publicly-available the implementations of algorithms we develop. To evaluate our methods, we will apply them to standard benchmarks, e.g., ImageNet and CIFAR10; and to “stress test” our methods in a realistic application, we will apply them to data (TBD) from the BDD project.
References
- Ray. https://rise.cs.berkeley.edu/projects/ray/.
- A. Gittens, K. Rothauge, M. W. Mahoney, S. Wang, and J. Kotaalam. Alchemist: An Apache Spark <=> MPI interface. Manuscript. 2018.
- S. B Kylasa, F. Roosta-Khorasani, M. W. Mahoney, and A. Grama. Sub-sampled Newton methods on GPUs. Manuscript. 2018.
- Michael W Mahoney. Randomized algorithms for matrices and data. Foundations and TrendsQR Learning, 3(2):123–224, 2011. in Machine
- Farbod Roosta-Khorasani and Michael W Mahoney. Sub-sampled Newton methods I: globally convergent algo- rithms. arXiv preprint arXiv:1601.04737, 2016.
- Farbod Roosta-Khorasani and Michael W Mahoney. Sub-sampled Newton methods II: Local convergence rates. arXiv preprint arXiv:1601.04738, 2016.
- Shusen Wang, Farbod Roosta-Khorasani, Peng Xu, and Michael W Mahoney. GIANT: Globally Improved Ap- proximate Newton Method for Distributed Optimization. arXiv preprint arXiv:1709.03528, 2017.
- Peng Xu, Farbod Roosta-Khorasani, and Michael W. Mahoney. Newton-Type Methods for Non-Convex Opti- mization Under Inexact Hessian Information. arXiv preprint arXiv:1708.07164, 2017.
- Peng Xu, Farbod Roosta-Khorasani, and Michael W. Mahoney. Second-Order Optimization for Non-Convex Machine Learning: An Empirical Study. arXiv preprint arXiv:1708.07827, 2017.
| principal investigators | researchers | themes |
|---|---|---|
| Michael Mahoney | second-order optimization, GPU optimization, trust region methods, optimizing batch size and learning rate |