Learning Timely Ego-centric Visual Attention for Smooth Driving
ABOUT THE PROJECT
At a glance
In driving, timing is everything. We propose to learn timely ego-centric visual attention in order to achieve a smooth autonomous driving performance. The challenges lie in discovering what to pay attention to from lots of driving data without any annotations. The key is timing between seeing and steering.
Given First-Person images, we predict objects the camera wearer is paying attention to as we move. For driving, we recognize what an experienced driver is paying attention to in order to keep space to avoid car accidents.
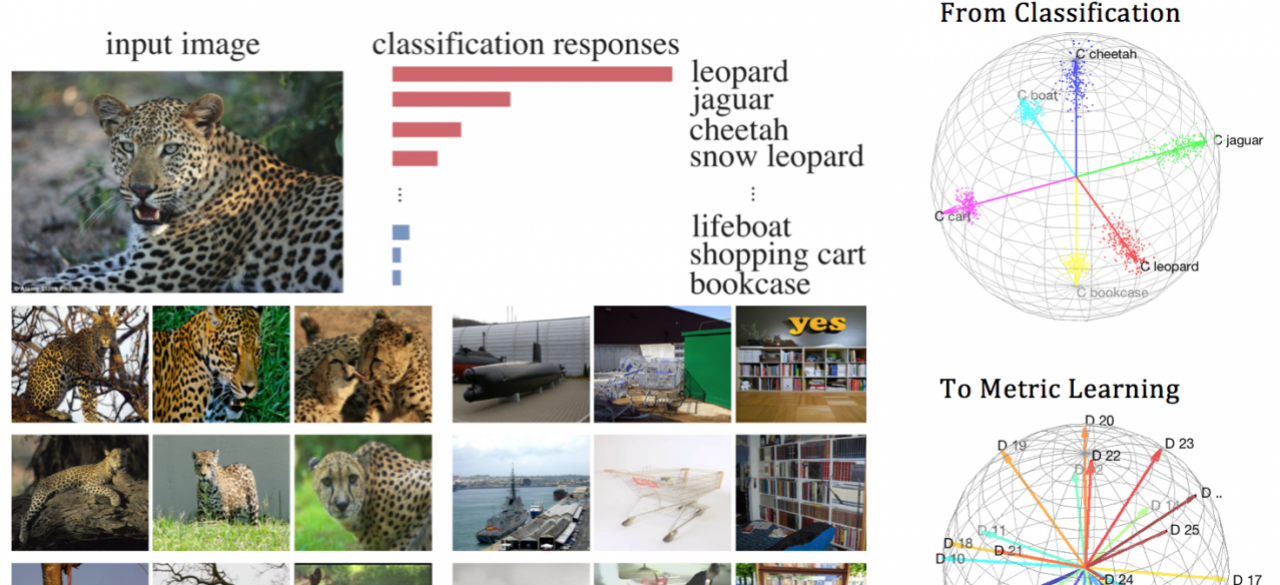
A first-person camera, placed at a person’s head, captures which objects are important to the camera wearer. Most prior methods for this task learn to detect such important objects from the manually labeled first-person data in a supervised fashion. However, important objects are strongly related to the camera wearer’s internal state such as his intentions and attention, and thus, only the person wearing the camera can provide the importance labels. Such a constraint makes the annotation process costly and limited in scalability. In a series of related publications, we show that we can detect important objects in first-person images with or without the supervision by the camera wearer or even third-person labelers. We formulate an important detection problem as an interplay between the 1) segmentation and 2) recognition agents. The segmentation agent first proposes a possible important object segmentation mask for each image and then feeds it to the recognition agent, which learns to predict an important object mask using visual semantics and spatial features. We implement such an interplay between both agents via an alternating cross-pathway supervision scheme inside our proposed Visual-Spatial Network (VSN). Our VSN consists of spatial (“where") and visual (“what") pathways, one of which learns common visual semantics while the other focuses on the spatial location cues. Our unsupervised learning is accomplished via a cross-pathway supervision, where one pathway feeds its predictions to a segmentation agent, which proposes a candidate important object segmentation mask that is then used by the other pathway as a supervisory signal. We show our method’s success on two different important object datasets, where our method achieves similar or better results as the supervised methods.
Given First-Person images, we predict objects the camera wearer is paying attention to as we move. For driving, we recognize what an experienced driver is paying attention to in order to keep space to avoid car accidents.
A first-person camera, placed at a person’s head, captures which objects are important to the camera wearer. Most prior methods for this task learn to detect such important objects from the manually labeled first-person data in a supervised fashion. However, important objects are strongly related to the camera wearer’s internal state such as his intentions and attention, and thus, only the person wearing the camera can provide the importance labels. Such a constraint makes the annotation process costly and limited in scalability. In a series of related publications, we show that we can detect important objects in first-person images with or without the supervision by the camera wearer or even third-person labelers. We formulate an important detection problem as an interplay between the 1) segmentation and 2) recognition agents. The segmentation agent first proposes a possible important object segmentation mask for each image and then feeds it to the recognition agent, which learns to predict an important object mask using visual semantics and spatial features. We implement such an interplay between both agents via an alternating cross-pathway supervision scheme inside our proposed Visual-Spatial Network (VSN). Our VSN consists of spatial (“where") and visual (“what") pathways, one of which learns common visual semantics while the other focuses on the spatial location cues. Our unsupervised learning is accomplished via a cross-pathway supervision, where one pathway feeds its predictions to a segmentation agent, which proposes a candidate important object segmentation mask that is then used by the other pathway as a supervisory signal. We show our method’s success on two different important object datasets, where our method achieves similar or better results as the supervised methods.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Stella Yu | Gedas Bertasius | Action-Object Detection |