Learning Video Models Using VQ-VAE and Transformers
ABOUT THIS PROJECT
At a glance
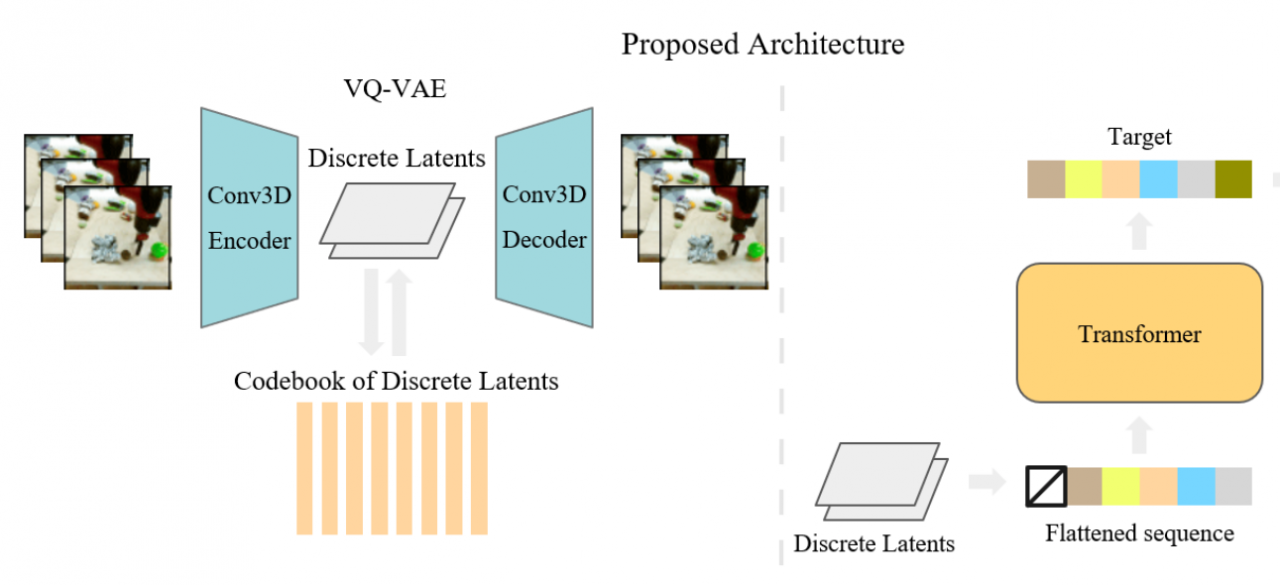
Developments in generative modeling for natural images have seen tremendous progress over the last few years, where SOTA generative models are able to produce realistic, diverse, and high-resolution samples from complex image datasets [1,2,3,4,15]. Generating complex videos presents itself as a further challenge for the area of generative modeling, primarily due to increased data and computational complexity. In comparison to images, generating high-fidelity and coherent video samples requires a generative model to learn about motion, object interactions, and perspective, all of which are necessities for bringing intelligence into the real world. Applied to the real world, video generation models can be extended to a suite of conditional generative video models that can be used for a wide variety of tasks, such as future video prediction, forecasting semantic abstractions for autonomous driving [20], and world modeling. Analogous prior work [7, 12, 16. 17, 18] in representation learning for images shows that generative models for videos might also learn useful features that can possibly be applied to downstream tasks such as video action classification.
Recent work in video generation has focused on incorporating better inductive biases and designing more computationally efficient model architectures [9, 19, 21, 22]. However, most proposed models are GAN-based architectures that are prone towards mode collapsing and thus tend to have lower sample diversity. In addition, although some works have succeeded in generating larger spatial resolution samples (256 x 256), scaling to larger temporal resolutions remains to be a difficult task, as latest methods are only able to generate maximum a couple seconds of coherent video (<60 frames), a crucial problem to solve when extending to the real world.
| Principal investigators | researchers | themes |
|---|---|---|
| Pieter Abbeel | Deep Learning, Computer Vision, Video Generation, Unsupervised Learning |