Maneuver Control based on Reinforcement Learning for Automated Vehicles in an Interactive Environment
ABOUT THE PROJECT
At a glance
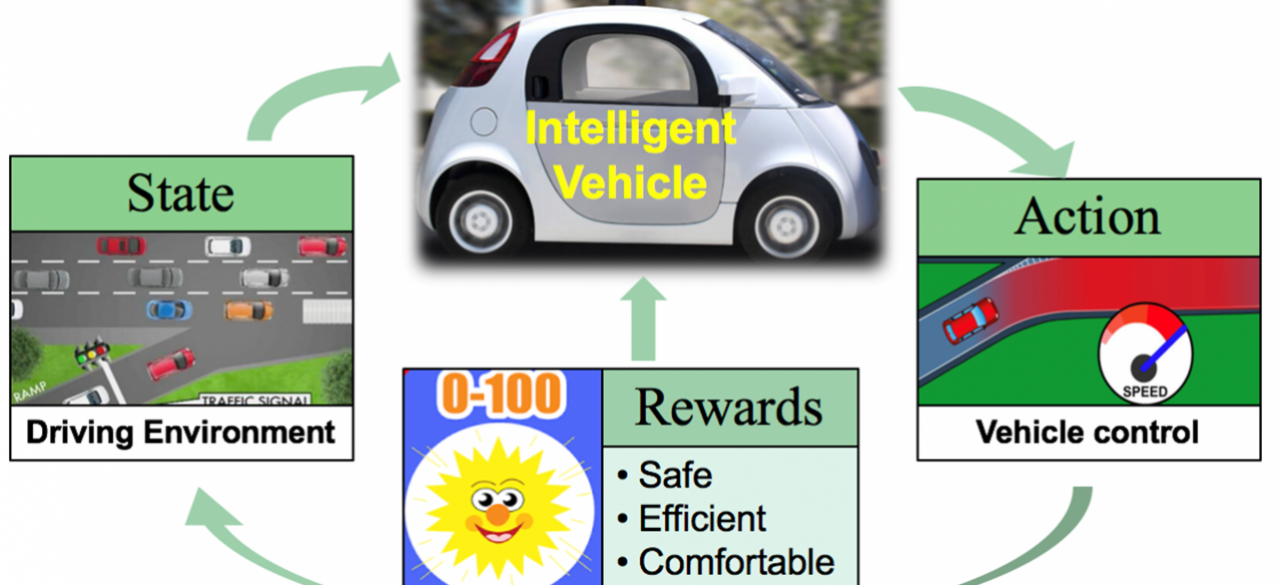
Tough challenges frequently arise in automated driving domains, especially when the vehicle is under an interactive and dynamic driving environment. The automated vehicle needs not only to avoid collisions with objects either in motion or stationary, but also to coordinate with surrounding vehicles so as not to disturb the traffic flow adversely when it executes a maneuver. The most challenging part is that the reaction from surrounding vehicles may be highly unpredictable. For example, in a lane change maneuver the trailing vehicle in the target lane may respond cooperatively (e.g. decelerate or change lane to yield to the ego vehicle) or adversarially (e.g. accelerate to deter the ego vehicle from cutting into its course. Thereby, controlling the automated vehicle for safe and effective driving under an interactively dynamic environment is of great importance for the deployment of automated driving systems.
Vehicle driving maneuvers are essentially time sequential problems and the current action has a cumulative impact on the ultimate goal of the task (e.g. a safe and comfortable lane change/ramp merge). Therefore, we propose a reinforcement learning based approach to train the vehicle agent for safe, comfortable, and efficient maneuvers under interactive driving situations. Additionally, we formulate the vehicle control maneuvers with continuous state and action space to enhance the practicability and feasibility of the proposed approach.
To be specific, we apply value based reinforcement learning approach (Q-learning) for finding the optimal policy by designing a variant form of the Q-function approximator that consists of neural networks and additionally has a closed-form greedy policy. The designed deep Q-network is close to the idea of Normalized Advantage Function where we use a quadratic format to build the function structure.
We applied the proposed approach in two use case, the ramp merging scenario and lane changing scenario. One prominent advantage of the proposed approach is that the quadratic Q-function approximator avoids the complication of invoking an additional action function/network that learns to take actions as in the actor-critic algorithms, thus improving the computation efficiency.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Dr. Ching-Yao Chan | Pin Wang | Reinforcement Learning Autonomous Driving |