Mid-Level Visual Representations for Visuomotor Policies
ABOUT THIS PROJECT
At a glance
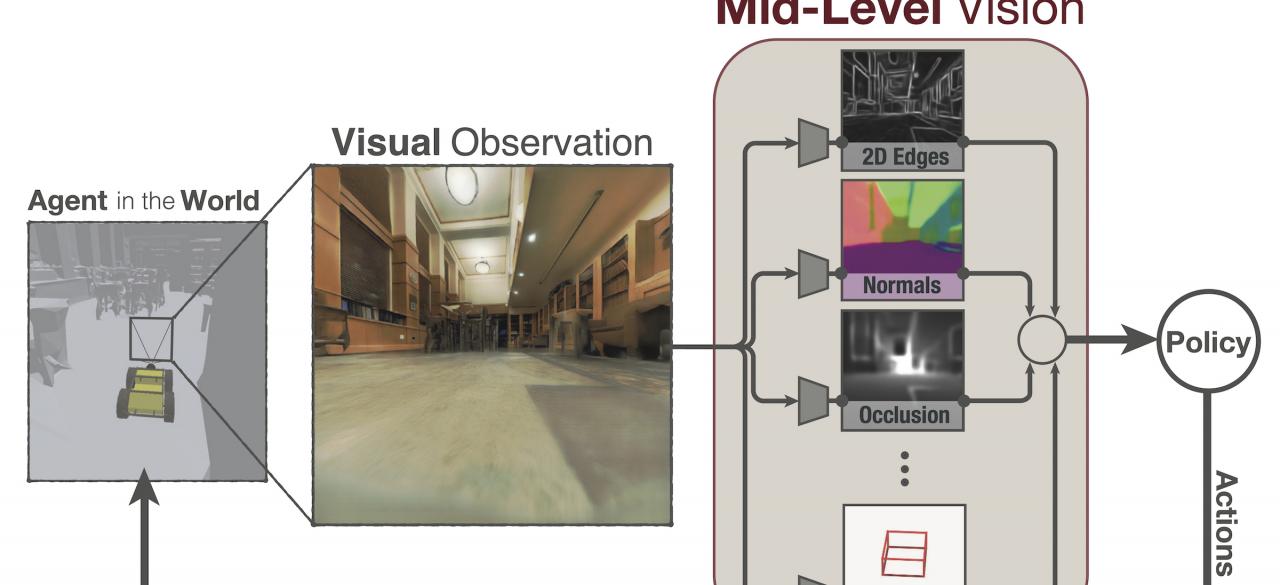
How much does having visual priors about the world (e.g. the fact that the world is 3D) assist in learning to perform downstream motor tasks (e.g. navigating a complex environment)? What are the consequences of not utilizing such visual priors in learning? We propose to investigate these questions by integrating a generic perceptual skill set (a distance estimator, an edge detector, etc.) within a reinforcement learning framework (see Fig. 1). This skill set (“mid-level vision”) provides the policy with a more processed state of the world compared to raw images.
Recent results that suggest that using mid-level vision results in policies that learn faster, generalize better, and achieve higher final performance, when compared to learning from scratch and/or using state-of-the-art visual and non-visual representation learning methods. In this project we propose a large-scale study to investigate which mid-level vision objectives are useful, and when. Specifically, we propose to compare conventional computer vision objectives to learning from scratch or using state-of-the-art representation learning methods by incorporating these into a reinforcement learning frameworks. Preliminary results suggest that conventional computer vision results are particularly effective. Moreover, we should expect that no single visual representation could be universally useful for all downstream tasks. We therefore propose a computationally derived a task-agnostic set of representations optimized to support arbitrary downstream tasks.
| Principal Investigators | Researchers | Themes |
|---|---|---|
| Jitendra Malik | Alexander Sax | Computer Vision, Representation Learning, Autonomous Navigation, Mid-Level Vision, Perception |