Outdoor Semantic Scene Segmentation via Multi-modal Sensor

About This Project
At a glance
Semantic understanding of environments is an important problem in robotics in general and intelligent autonomous systems in particular. Semantic segmentation involves labeling every pixel in an image, or point in a point cloud, with its corresponding semantic tag. A semantic understanding of the environment facilitates robotics tasks such as navigation, localization, and autonomous driving. This project will build upon the team’s previous work to develop a class of semantic segmentation algorithms which effectively fuse information from images and 3D point clouds.
The team will extend a previously developed algorithm to take into account the time domain and time-sequential images and Lidar. Incorporating temporal data can be useful in two ways: first for static scenes, the images and Lidar data obtained from a moving platform could significantly improve the semantic segmentation due to the temporal redundancy of both modalities, even though this is achieved at the expense of increased computation. More importantly, time sequential data can be useful for tracking moving objects such as cars, bicycles, and pedestrians.
Even though the problem of object tracking for cars and pedestrians from stationary cameras has been studied extensively, there are extra challenges when the camera and the object under consideration are both moving. The team has developed and implemented a preliminary version of tracking in video imagery for specific objects and object classes for an extended time. The addition of the time domain also indicates the significant gain the team expects to achieve in the accuracy and resolution of the segmentation based on the visual and Lidar data, however, at the cost of computing time.
The team will extend a previously developed algorithm to take into account the time domain and time-sequential images and Lidar. Incorporating temporal data can be useful in two ways: first for static scenes, the images and Lidar data obtained from a moving platform could significantly improve the semantic segmentation due to the temporal redundancy of both modalities, even though this is achieved at the expense of increased computation. More importantly, time sequential data can be useful for tracking moving objects such as cars, bicycles, and pedestrians.
Even though the problem of object tracking for cars and pedestrians from stationary cameras has been studied extensively, there are extra challenges when the camera and the object under consideration are both moving. The team has developed and implemented a preliminary version of tracking in video imagery for specific objects and object classes for an extended time. The addition of the time domain also indicates the significant gain the team expects to achieve in the accuracy and resolution of the segmentation based on the visual and Lidar data, however, at the cost of computing time.
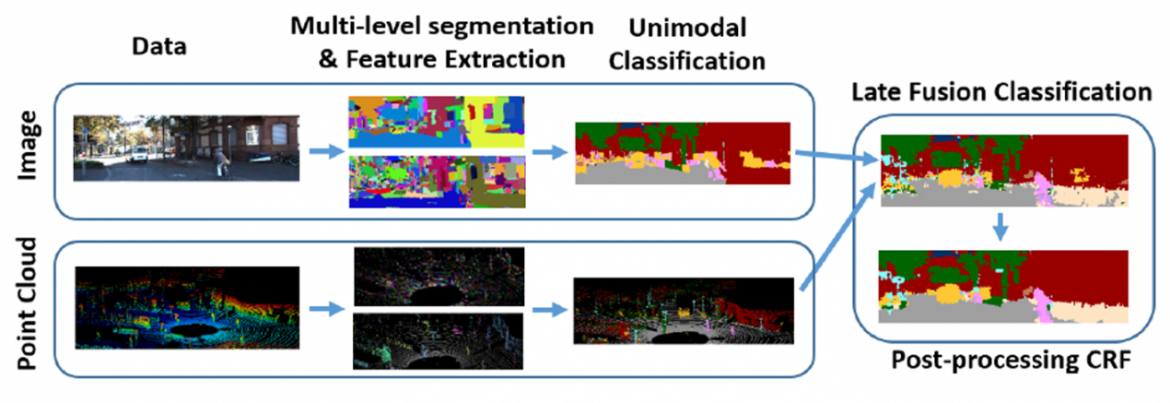
Illustration below shows top-level data pipeline.
| Principal Investigators | Researchers | Themes |
|---|---|---|
| Avideh Zakhor | Stefan A. Candra Kai Vetter Richard Zhang | Semantic Segmentation Automotive Visioning |