Robust Perception for Autonomous Driving

ABOUT THE PROJECT
At a glance
Current deep learning classifiers are not robust and are susceptible to adversarial examples that could be used to fool the classifier and manipulate autonomous vehicles. We will study how to make deep learning classifiers robust against these attacks.
Background Recent research has shown that deep learning for images is fragile and susceptible to attack: adversaries can craft images that fool the machine learning and cause the system to make poor decisions. For instance, Sitawarin et al. show how to generate malicious signs that fool a road sign classifier: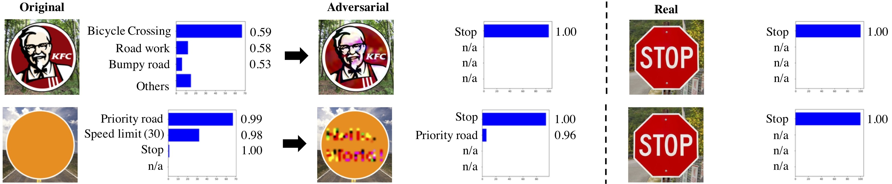
and a recent BDD project from PIs Darrell and Song demonstrated that these attacks are serious and practical, by generating signs that are mis-recognized by standard classifiers:
It is currently an open problem how to prevent these problems. We will study how to construct deep learning models that are robust against such attacks.
Proposed approach. Our approach will be to build a self-checking classifier, where the classifier outputs not only a label (e.g., what type of sign it is), but also a “proof”—evidence that its classification is correct. Then, we will build a proof-checker that validates this evidence against the original image. In pictures, our proposed approach is:
We are inspired by the observation that it is often easier to check the correctness of a proposed solution than it is to find the solution. Here, the checker can hopefully be much simpler than the classifier, and thus easier to harden against attack. This architecture also allows us to use any stateof-the-art classifier for classification itself, allowing the architecture to keep up with advances in computer vision, while adding security against adversarial examples in a separable component.
This approach is inspired by work on explainable AI, though here we seek to generate explanations (“proofs”) that will be consumed by an automated proof checker, rather than by a human. Thus, the nature of explanations required is a bit different. For road signs, there is a path towards constructing a checkable explanation: if I wanted to convince you that this is a picture of a stop sign, I might tell you that it has an octagonal shape with a red interior, has an “S”, has a “T”, a “O”, and a “P”—and with each of these shapes in locations that are consistent with a stop sign. In pictures: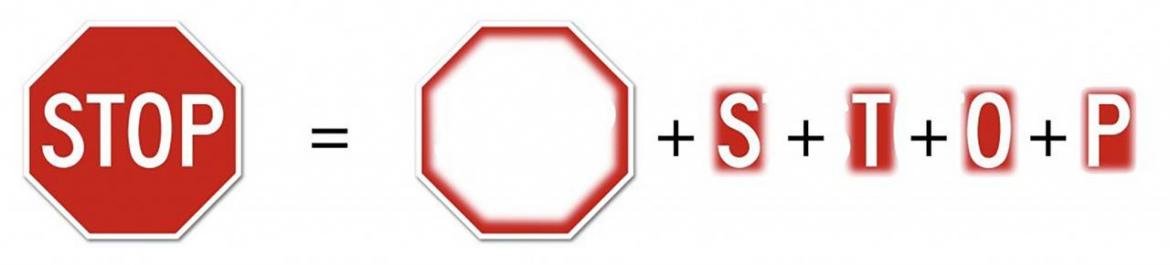
Thus, to generate a proof that the input is a stop sign, the classifier must locate an octagonal shape, an “S” shape, a “T” shape, an “O” shape, and a “P” shape. The proof consists of the locations of these shapes. The proof-checker must then verify that each of these shapes are present at the claimed locations, and that these locations are consistent with a stop sign. Because the shapes are especially simple and uniform, we expect it may be possible to harden the proof-checker against adversarial examples.
We propose to begin our study of this approach by exploring recognition of road signs. Can we recognize standard signs, with little or no loss of accuracy? Does this approach resist attack?
| principal investigators | researchers | themes |
|---|---|---|
| David Wagner | Machine Learning, Security, Adversarial examples, Traffic signs |