Spatial and Visual Memory for Navigation
ABOUT THE PROJECT
At a glance
Motivation
As humans we are able to effortlessly navigate through environments. We can effectively plan paths, find shortcuts, and adapt to changes in the environment, while only having a relatively coarse sense of the exact geometry of the environment or the exact egomotion over long distances. Human representations for space [6] start out from destination knowledge, which is a set of places of interest. This guides acquisition of route knowledge of specific routes to go from one destination to another. Already at this point, humans exhibit an impressive ability to follow routes reliably in the presence of changes in the environment (demolition / construction of buildings, appearance variations due to change in seasons, and the time of day), as well as, uncertainty in estimate of their egomotion and location in space. This is facilitated by the use of distinctive landmarks (such as clock towers) that are invariant to changes in the environment and provide visual fixes to collapse the uncertainty in location. As more and more of such route knowledge is experienced over time, it is assimilated into survey knowledge, which is knowledge of the spatial layout of different places and routes with respect to one another. It is at this point that humans are also able to plan paths to novel places and find shortcuts for going between different known points. This is generally accomplished by reasoning over a coarse spatial layout of places through a cognitive map [5]. This remarkably human navigation ability is driven by both map based and landmark based representations. Map based representations allow for planning paths and finding shortcuts, while landmark based visual memory of the environment permits executing the planned path in the presence of noisy and uncertain motion. At the same time, humans use their prior experience with other similar environments to construct reasonable path plans with only partial knowledge of a new environment.
Of course, there is vast literature in robotics that studies navigation. Classical approaches operate purely geometrically: a) a geometric map, that comprises of a 3D reconstruction of the world, is built from observed images and sensor readings, b) localization in this map happens through geometric consistency of matched feature points, and c) path plans are computed by explicitly rolling out system dynamics in occupancy maps. Such reliance on explicit hand-crafted representations limits the performance and robustness of these classical methods in many ways. Classical geometry-based approaches operate purely based on explicit observations, and ignore statistical priors (experience from similar other environments), that can be used to make meaningful speculations about unobserved parts of the environment. At the same time, classical methods rely on always being able to localize the agent in the map. Precise localization is challenging (such as in long texture-less hallways, or in dynamic environments), specially using purely hand-crafted features and geometric reasoning; at the same time it may not even be necessary at all times. Finally, individual modules in classical pipelines can not be trained jointly. This makes them hard to design and optimize, given surrogate metrics that may not correlate with the performance of the overall system. Contemporary learning based approaches [4, 8] have focused on incorporating statistical priors, making localization implicit, and jointly optimizing for the end task. But, they have completely ignored the question of representation of spaces by making it completely implicit in the form of neural network activations.
In this project, we want to pursue rich and expressive representations for spaces that can be learned from data in a task-driven manner. But crucially, in departure from contemporary learning based efforts, we want to build space representations that allow for novel path planning, finding shortcuts, and robust execution of planned paths in dynamic environments, while at the same time only using limited amount of interaction with a novel environment.
Proposed Approach
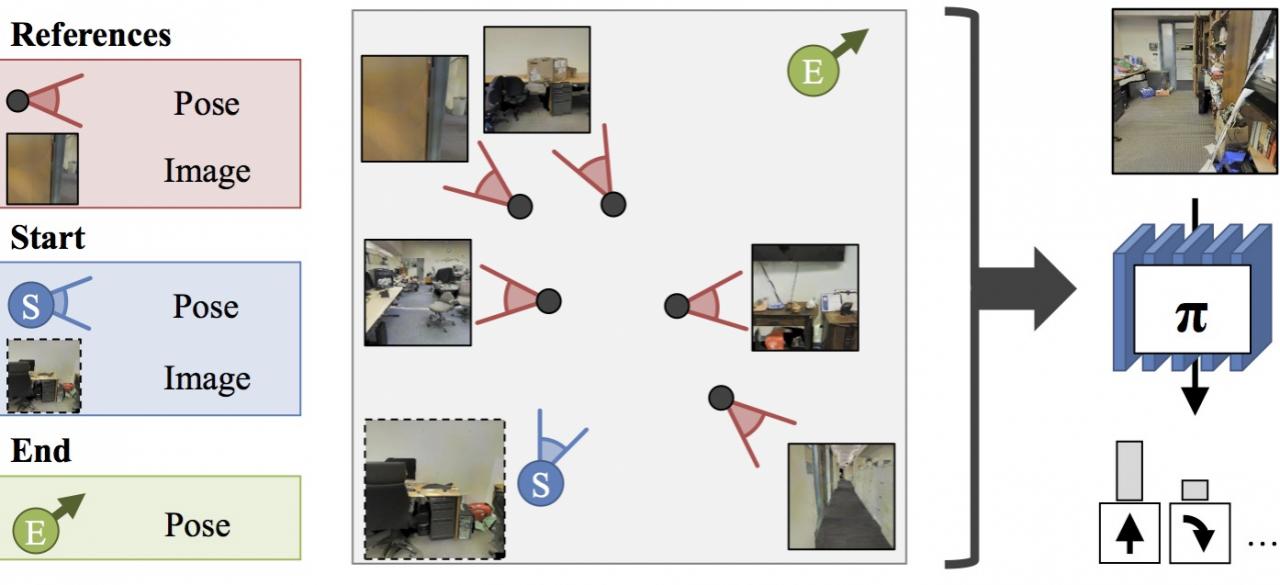
In this project, we propose to build map and landmark based representations for spaces: map based representations are used for spatial reasoning to plan paths and find shortcuts [2], while past visual memories are used to derive visual fixes (landmarks) to reliably follow planned paths under noisy actuation and changes in the environment [3].
Our map based representation (shown in Figures 1 and 2), absorbs observations made by the robot into a spatial memory that serves as map for doing path planning. Both the mapping function and the planning computation can be done differentiably, allowing joint end-to-end training of the mapper and the planner. This enables training of the mapping and planning modules on data, allowing us to leverage statistical regularities of the real world and making speculations about unseen parts of the environ- ment. At the same time, the mapping process is driven by the needs of the planner, leading to more expressive representations over just capturing space occupancy as done by traditional methods.
Given the plan output by the proposed unified mapping and planning system, we design a goal-driven closed-loop controller to execute the plan under noisy actuation and changing environment (shown in Figure 1(right)). We augment the plan (sequence of actions to reach the goal), with a path signature that additionally describes the features on the way to the goal. This path signature can then be used for closed-loop control: if expected features aren’t seen, relatively simple, local, error correction strategies can be used to take corrective actions without explicit having to re-localization and re-planning. As before, generation and path signatures, and their usage to take actions are learned together. This leads to learning path signatures that are robust to changes in the environment, and useful for reliably navigating around in the environment. Finally, such a learning setup can
Figure 1: Unified mapping and planning architecture and preliminary experimental validation (left), path signatures and path following policy archi- tecture and preliminary experimental validation (right).
Figure 2: Architecture of the mapper (left) and the planner (right).
also learn to express plans more semantically as it has the flexibility to encode more abstract behavior (such as going down the freeway, taking the next exit, etc.). Such semantic plans are more robust than geometric plans (such as go straight 31.4159 miles and take a 56◦ turn), and at the same time, do not require precise localization at all times.
Our approach is reminiscent of classic robotics pipelines, but with the crucial distinction that, instead of using geometry- based, hand-defined, isolated modules, we propose a differentiable, end-to-end trainable, data-driven formulation. Classical approaches are driven entirely by explicit geometry and have no way to incorporate statistical priors. They also require design of intermediate representations that are hard to design and even harder to optimize given surrogate metrics that do not always correlate with the final performance. In contrast, in our proposed formulation, learning allows use of statistical priors based on knowledge of similar other environments; enabling our method to work with only a handful of images. Joint optimization of modules alleviates the need to hand define intermediate representations that bottleneck the final performance, and modules can be trained together, allowing them to be robust the error-modes of one another.
Preliminary experimental investigation in simulations based on scans from real world office environments has shown promis- ing results. We have been able to train policies for getting to a location and finding objects of interests in novel environments with good success rates. Comparisons to adaptations of classical mapping and planning approaches as well as comparison to other neural network based policies with and without vanilla neural network memory are all favorable to our proposed architecture (shown in Figure 1(right)). Preliminary experiments with simple actuation noise models also show the utility of path signatures and learned policies for plan following.
Future Work
Extensions to autonomous driving: Most of our experiments so far have studied this problem for indoor mobile robots. It will be interesting to study the problem in context of autonomous driving, and investigate if the same insights apply to outdoor settings. While driving settings are often more structured, they involves much larger scale maps, and highly dynamic environments. We believe this will serve as a good test-bed for our hierarchical mapping and planning representations, as well as, for our landmark based semantic planning for robustly executing plans over long horizons. It will be particularly interesting to analyze if the set of landmarks considered useful by our proposed algorithms, matches our perceived notion of landmarks as humans. Existing driving simulation environments such as CARLA [1] will be a natural experimental setup.
Using more natural supervision: Our current solution also relies on a simulation environment for generating supervision necessary for training our proposed models. It will be interesting to investigate, how we can move towards more natural ways of acquiring navigational expertise, through reinforcement learning or self-supervised learning that does not assume access to an omniscient oracle. Enabling such methods to learn from dash-cam driving videos (such as the ones in the Nexar dataset [7]), will further extend the applicability of our approach.
Towards continuous control: In our current work, we have abstracted away low-level control of robot agents by using simple discrete action spaces. While these choices have enabled fast progress, it is desirable for real robots and cars to move smoothly. Integration of our map and landmark based representation with continuous control methods is also an important research direc- tion. Our work already factors out the space representation from the controller that actually executes actions. Future work will focus on design of controllers that are aware of the system dynamics, thereby leading to smooth motion.
References
1) A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. CARLA: An open urban driving simulator. In CoRL, pages 1–16, 2017.
2) S. Gupta, J. Davidson, S. Levine, R. Sukthankar, and J. Malik. Cognitive mapping and planning for visual navigation. In CVPR, 2017.
3) S. Gupta, D. Fouhey, S. Levine, and J. Malik. Unifying map and landmark based representations for visual navigation. arXiv preprint arXiv:1712.08125, 2017.
4) P. Mirowski, R. Pascanu, F. Viola, H. Soyer, A. Ballard, A. Banino, M. Denil, R. Goroshin, L. Sifre, K. Kavukcuoglu, et al. Learning to navigate in complex environments. In ICLR, 2017.
5) E. C. Tolman. Cognitive maps in rats and men. Psychological review, 1948.
6) J. M. Wiener, S. J. Bu¨chner, and C. Ho¨lscher. Taxonomy of human wayfinding tasks: A knowledge-based approach. Spatial Cognition & Computation, 9(2):152–165, 2009.
7) H. Xu, Y. Gao, F. Yu, and T. Darrell. End-to-end learning of driving models from large-scale video datasets. arXiv preprint arXiv:1612.01079, 2016.
8) Y. Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In ICRA, 2017.
| PRINCIPAL INVESTIGATORS | RESEARCHERS | THEMES |
|---|---|---|
| Jitendra Malik | Saurabh Gupta and Ashish Kumar | Mobile robots, Navigation, Visual landmarks, Map building |