Systematic Quantization on Vision Models for Real-time and Accurate Inference in ADAS/AV
ABOUT THIS PROJECT
At a glance
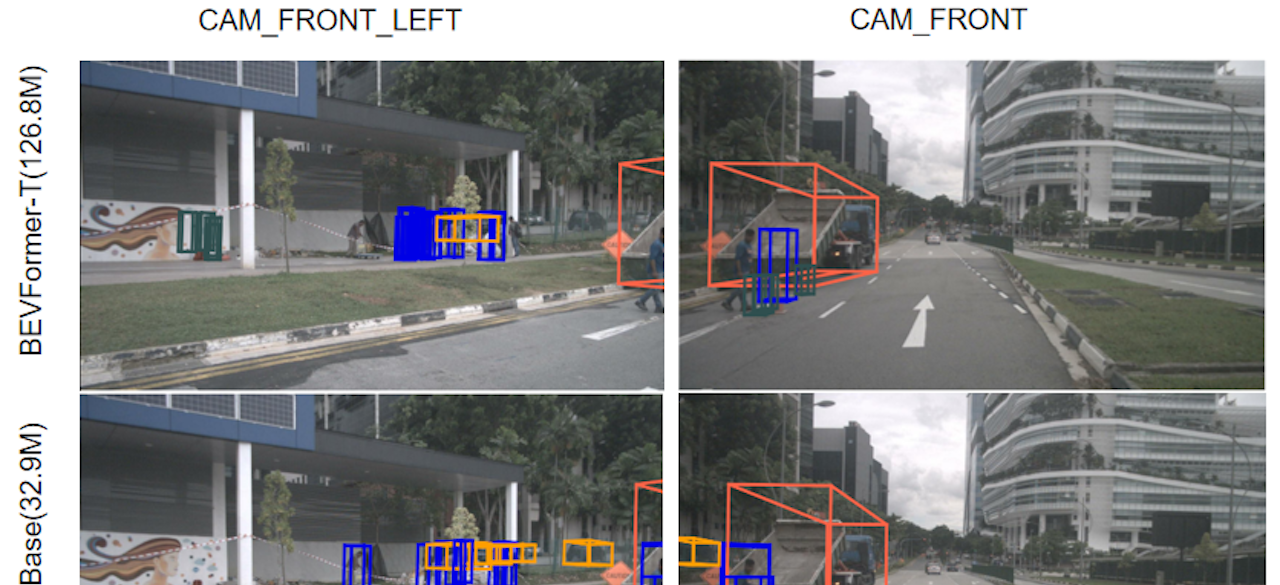
The primary focus of mainstream deep learning research is increasing the accuracy of neural networks (NNs). However, in real-world applications, there are often constraints on the latency of the NN's inference. To add to this challenge, many automotive applications must run on edge processors with limited computational power. As a result, practitioners often need to use shallow networks with lower accuracy to avoid latency issues. A potential solution is to quantize the weights and activations of NN models, which makes them feasible on embedded hardware. However, current quantization methods often use random heuristics that require a high computational cost, and typically only target CNN-based models. In this project, our goal is to systematically study quantization on various neural architectures and on various applications that are particularly relevant to ADAS/AV. In previous projects, we have developed two Hessian-based quantization frameworks, HAWQ and ZeroQ. We plan to further improve these frameworks by 1) analyzing the challenge of large quantization ranges of activations in state-of-the-art transformer-based vision models, 2) creating a better quantization strategy designed for vision transformers, 3) studying the quantization methods (both PTQ and QAT) for multi-view 3D object detection tasks in autonomous driving, and 4) proposing specially designed quantization techniques to achieve better speedup and stability for BEV (bird-eye-view) models.
| principal investigators | researchers | themes |
|---|---|---|
| Kurt Keutzer | Xiuyu Li Sehoon Kim | Quantization, Efficient Inference, Model Compression, Multi-view 3D Object Detection, Bird-eye-view (BEV), Transformers, Efficient Deep Learning |