Training Data Augmentation for Autonomous Driving
ABOUT THIS PROJECT
At a glance
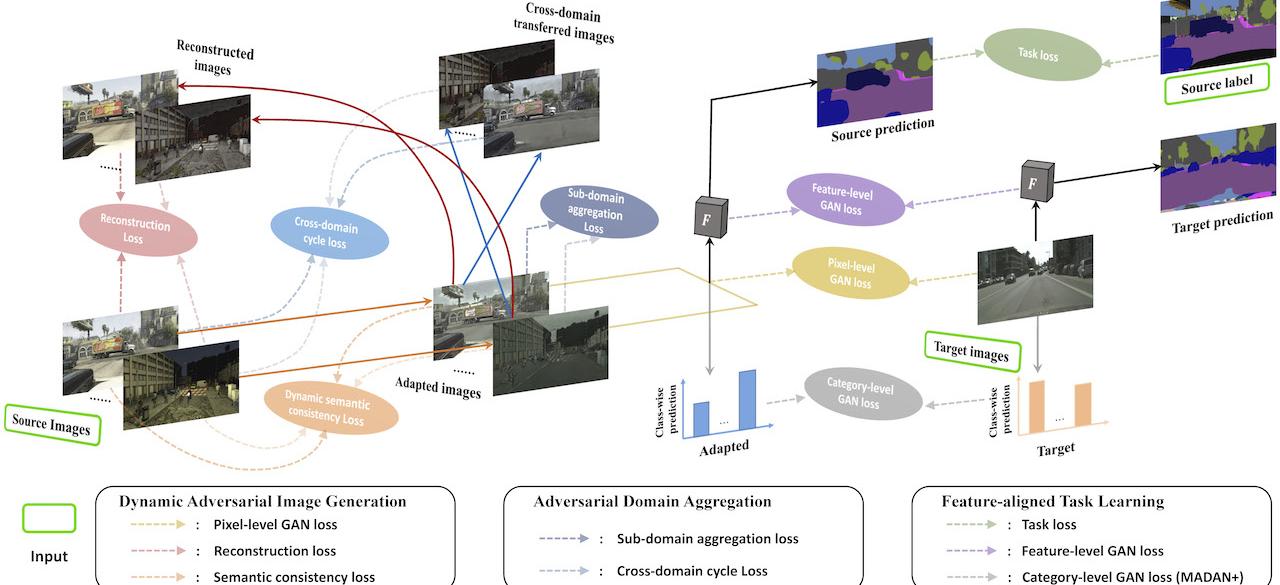
Recently, Deep Neural Networks (DNN) have achieved remarkable progress in many autonomous driving challenges, such as semantic segmentation and object detection. However, training DNN requires large-scale labeled datasets, which are expensive and time-consuming to obtain. There are several ways to augment training data and help obviate the need for time-consuming labeling. On the one hand, we can train DNN by utilizing the synthetic simulation data with automatically generated annotations (e.g. CARLA and GTA-V), and transfer the trained DNN to real-world data. Because of the presence of domain shift [Tzeng2015, Hoffman2018, Zhao2019], direct transfer does not perform well. For example, the mean intersection-over-union (mIoU) of FCN [Shelhamer2017] drops from 62.6% (if trained on real Cityscapes [Cordts2016]) to 18.5% (if trained only on synthetic SYNTHIA [Ros2016]). To address this problem, will develop a systematic domain adaptation and domain randomization framework.
| principle investigators | researchers | themes |
|---|---|---|
| Kurt Keutzer | Xiangyu Yue Shanghang Zhang | training data augmentation, autonomous driving, domain adaptation, domain randomization, few-shot learning, self-supervised learning |