A Unified Generative Framework for 3D Driving Scenarios
ABOUT THIS PROJECT
At a glance
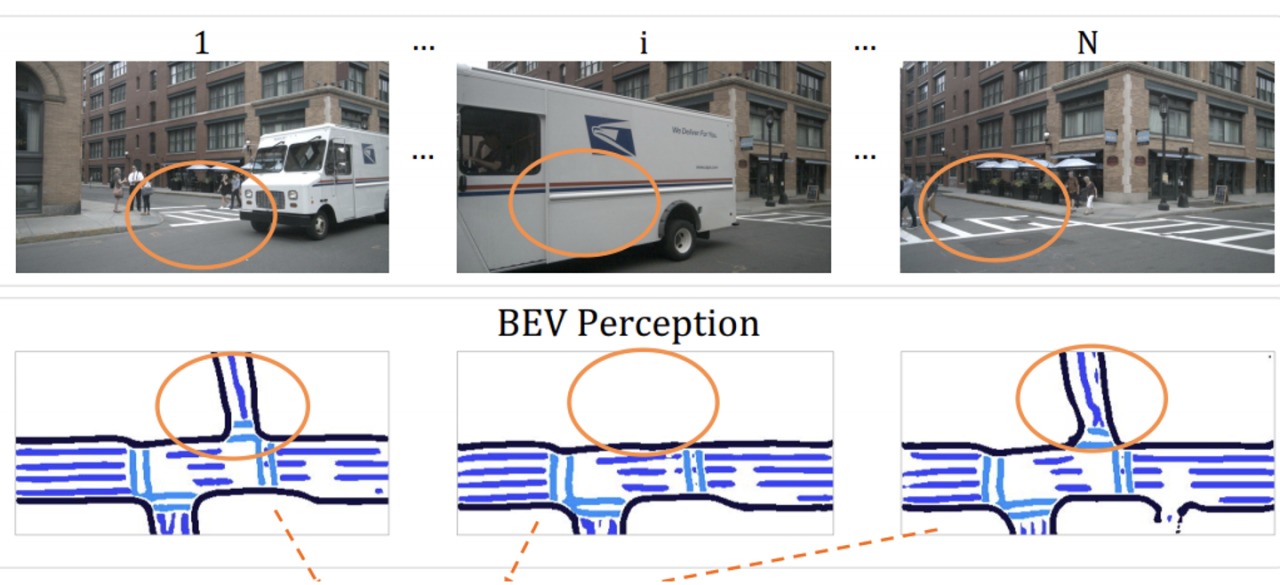
A large amount of synthetic data with high-quality annotations is desirable for the field of autonomous driving. To fill in this gap, previous research has applied latent diffusion models (LDM) [1] to the generation of multi-view images [2], front-view videos [3,4], or panoramic videos [5,6]. However, these methods can only generate the street scene without corresponding annotations. To obtain annotated scenes, these algorithms typically have to condition the generative process on some known layouts, represented by HD-map or object bounding boxes. Despite the controllability of generation brought by these conditions, they also limit the diversity of outputs. In comparison, it is more desirable that the diffusion model can generate diverse multi-view scenes along with high-quality fine-grained annotations simultaneously. Recent works [7,8] already show that diffusion models have internal representations suitable for dense perception tasks. Consequently, we suggest lifting the internal representation to the 3D space so that we can easily attach additional perception heads to the 3D latent space. It can output extra fine-grained annotations such as HD-map or object bounding boxes in the generative process. Notably, our framework can flexibly take in partial information about the scene as the condition for the generation and output the fine-grained annotations of the entire scene along with high-quality multi-view images or videos.
Besides, the generation of videos is often conditioned on single-frame image inputs [3,4,5,6], which leads to inevitable hallucinations, especially in the occluded areas (e.g. blocked by large trucks). To this end, we get inspiration from 3D object detection methods [9] to temporally fuse several historical frames to get more reliable conditions for the generative process. The multi-view and temporal consistent generation can be used for various tasks, including scene generation, HD-map generation, and others.
| principal investigators | researchers | themes |
|---|---|---|
| 3D generation, HD map construction, vision-based scene understanding |