Efficient Neural Networks through Systematic Quantization
ABOUT THE PROJECT
At a glance
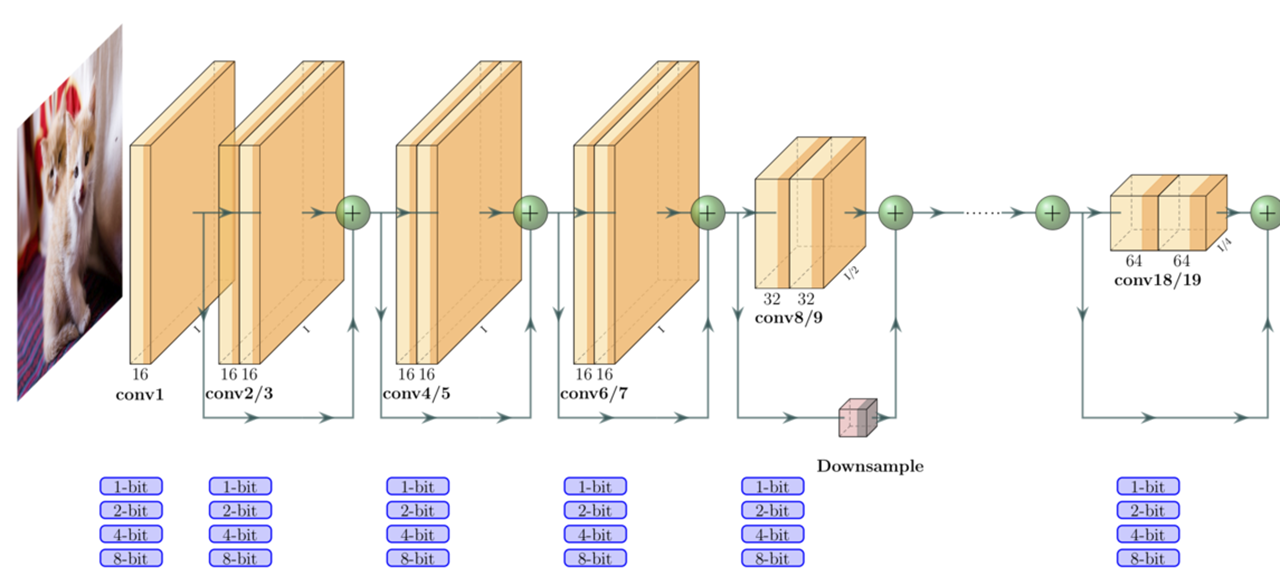
An important barrier in the deployment of deep neural networks is latency, which is a critical metric for autonomous driving. Despite a common misunderstanding, this latency directly affects the accuracy of NNs, since there are hard real-time constraints for autonomous driving. High latency translates to delayed recognition of a car, pedestrian, or a barrier in front of an autonomous agent in time before we can make an appropriate decision/maneuver. For this reason, practitioners have been forced to use shallow networks with non-ideal accuracy to avoid the latency problem. A promising approach to address this problem is quantization, which reduces the memory footprint and latency of a NN model, and could enable more efficient inference on a custom accelerator or embedded hardware. However, the current state-of-the-art quantization methods involve random heuristics and require high computational cost associated with brute-force searching. So far we have developed two state-of-the-art quantization frameworks, HAWQ and ZeroQ which addresses the above. In this proposal, we plan to extend these frameworks by (i) developing an efficient implementation of quantized NNs for different target hardware platforms, (ii) extending ZeroQ/HAWQ to hardware aware quantization, (iii) developing a quantization aware Neural Architecture Search framework to design NNs that are easy for quantization and hardware implementation, and (iv) extending ZeroQ/HAWQ to extreme quantization cases such as binary/ternary weights.
| Principal investigators | researchers | themes |
|---|---|---|
| Kurt Keutzer Michael Mahoney | Dr. Amir Gholami | Model Compression, Quantization, Stochastic Second-Order, Power Consumption, Latency |
This project laid the groundwork for "Efficient Deep Learning for ADAS/AV Through Systematic Pruning and Quantization".