Efficient Deep Learning for ADAS/AV Through Systematic Pruning and Quantization
ABOUT THE PROJECT
At a glance
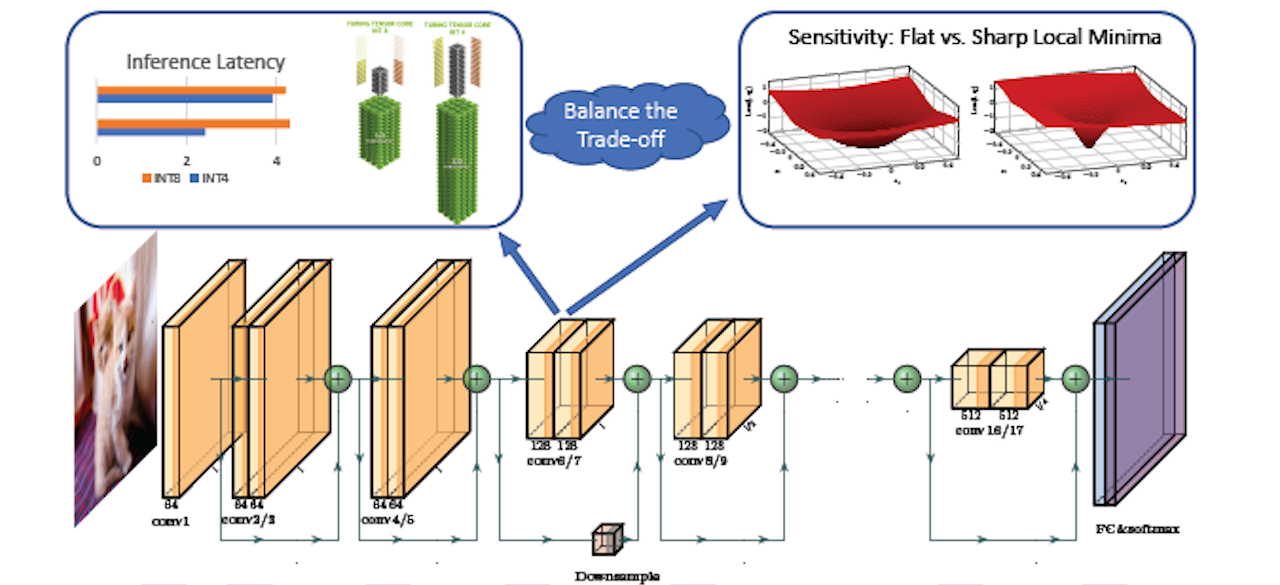
An important barrier in the deployment of deep neural networks is latency, which is critical for autonomous driving tasks. High latency can lead to delayed recognition of an object or a pedestrian in front of the car, making it challenging to take the appropriate maneuver in time. For this reason, practitioners have been forced to use shallow networks with non-ideal accuracy to avoid this latency problem. We plan to address this challenge by developing a systematic multi-faceted approach for end-to-end efficient NN design and deployment by pursuing the following thrusts: (i) developing a fast coupled quantization and pruning framework that allows the practitioner to obtain optimal trade-offs between accuracy, and speed for a given latency constraint; (ii) developing a quantization and pruning aware Neural Architecture Search co-designed for a target hardware platform for autonomous driving with limited power budget; and (iii) focusing on object detection and segmentation applications with 4K video stream. The outcome of this work will be an open-source framework that will automatically find an efficient NN architecture for the application-specific constraints of accuracy, latency, model size, and power consumption. This will build upon our recent works on quantization~\cite{dong2019hawq,dong2019hawqv2,yao2020hawqv3,cai2020zeroq}, pruning~\cite{yu2021hessian}, NAS~\cite{wu2018mixed,wu2019fbnet}, and the corresponding open source codes that have been contributed to BDD repository~\cite{hawqcode,zeroqcode,hapcode,pyhessian,fbnetcode}.
| principal investigators | researchers | themes |
|---|---|---|
Zhen Dong Sehoon Kim | Quantization, Pruning, Neural Architecture Search, Efficient Inference |
This is a continuation of the completed project: "Efficient Neural Networks Through Systematic Quantization" and the work in these projects have laid the groundwork for "Real-time and Accurate Object Detection through Systematic Quantization of Transformer and MLP-based Computer Vision Models".